Tuning Geocoding in Spark
Using Geocoding in Spark is a great way to quickly geocode millions of addresses but proper tuning is required to avoid failures and extended job times. This knowledge article will give general tuning advice and what to focus on when running your own data on your own cluster. This article is part 1 of 2 and will focus on geocoding a 19 million record dataset in an EMR cluster with 4 very large worker nodes. The second article will discuss advanced topics on techniques and calculations used in this post.
- Amazon Web Services (AWS):
- Elastic Map Reduce (EMR) - Used to create clusters of machines.
- Simple Storage Service (S3) - Used to store scripts and data to be downloaded to the EMR cluster.
- Spectrum Geocoding for Big Data:
- Spark 2 Geocoding Driver - Jar file used as-is to geocode in spark.
Data
The data we are going to geocode is a 1.25GB CSV file containing 19,385,996 addresses. Here is an example of the the data:
| id | address1 | address2 | address3 | city | state/province | postal code | country |
|---|---|---|---|---|---|---|---|
| 1 | 350 Jordan Road | Troy | NY | 12180 | USA | ||
| ... | |||||||
| 19385996 | 35 Railroad Row | Unit 1 | White River Junction | VT | 05001 | USA | |
The addresses are from over 200 countries.
Cluster
We are going to use the AWS EMR service to create a cluster comprised of 1 master node and 4 worker nodes. In order to determine the hardware specifications for our worker nodes we must determine an optimal size of our Spark Executors that will run our geocoding tasks. After doing tests, detailed next in Part 2, we will have spark executors that are 4 cores and 15GB of Memory. Based on this ratio of cores to memory we will use m5 EC2 cluster types since they have a similar hardware ratio of cores to memory. To determine the best m5 type we have to consider how many spark executors the type can allocate. Its important to remember that YARN, the service responsible for manage resources in an EMR cluster, will not allow spark to consume all of a node's memory. Go HERE to see YARN setting for each instance type.
| Instance Type | CPUs | Memory | Yarn Memory | # of 15GB Spark Executors | CPU Utilization | Notes |
|---|---|---|---|---|---|---|
| m5.xlarge | 4 | 16GB | 12GB | 0 | 0% | A memory restriction of 12GB will not allow any of our Spark Executor. |
| m5.2xlarge | 8 | 32GB | 24GB | 1 | 50% | A memory restriction of 24GB will only allow 1 Spark Executor, which leaves 4 CPU cores unused. |
| m5.4xlarge | 16 | 64GB | 56GB | 3 | 75% | A memory restriction of 56GB will only allow 3 Spark Executors, which leaves 4 CPU cores unused. |
| m5.12xlarge | 48 | 192GB | 184GB | 12 | 100% | All CPUs will be used if this instance type is chosen. |
| m5.24xlarge | 96 | 384GB | 376GB | 24 | 100% | All CPUs will be used if this instance type is chosen. |
If we want to use our resources efficiently then we have to either choose m5.12xlarge or m5.24xlarge. We decided to choose the smaller instance type m5.12xlarge. Since we will have 4 worker nodes then our cluster will be able to hold 47 Spark Executors. We cannot allocate 48 Executors because Spark needs space to run a Spark Driver which helps manages the Spark Job. Only 1 node will have the Spark Driver. Here is a diagram of our EMR Cluster:
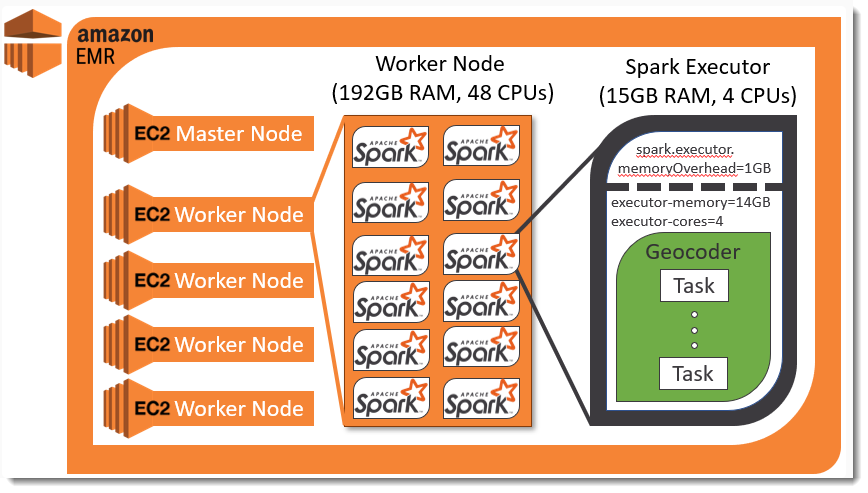
The cluster has custom bootstrap scripts that install geocoding when the nodes start up. This means the cluster is ready to geocode once it comes online.
Spark Application
To run our Spark application we will use the Spark Geocoding jar that is included in the product. We will not need to edit this jar because all the settings we need to change can be set as arguments. Here is the command used to execute the spark job:
spark-submit --master yarn --deploy-mode cluster --num-executors 47 --executor-cores 4 --executor-memory 14G --conf spark.executor.memoryOverhead=1G --driver-cores 1 --driver-memory 1GB --conf spark.driver.memoryOverhead=1GB --class com.pb.bigdata.geocoding.spark.app.GeocodeDriver /pb/geocoding/sdk/spark2/driver/spectrum-bigdata-geocoding-spark2-3.2.0-all.jar --geocoding-config-location /mnt/pb/geocoding/sdk/resources/config/ --geocoding-binaries-location /pb/geocoding/sdk/resources/nativeLibraries/bin/linux64/ --geocoding-preferences-filepath /pb/geocoding/sdk/resources/config/geocodePreferences.xml --input /user/hadoop/geocoding/test_data.txt --csv delimiter="|" --geocoding-input-fields mainAddressLine=1,2,3 areaName3=4 areaName1=5 postCode1=6 country=7 --output /user/hadoop/spark2/GeocodeDriverTester/should_geocode_addresses/output4 --geocoding-output-fields x y PB_KEY --error-field error --overwrite --num-partitions 1000Let's break that command down to explain it.
| Spark Script | |
|
Script supplied by Spark that allows us to submit spark applications. |
|
Run our Spark application on the worker nodes in our cluster. |
|
Create 47 executors, each having 4 cores and 15GB of total memory. |
| Spark Options | |
|
Explicitly declare driver resources to best manage cluster resources. We have enough extra resources to have the driver resource consumption mimic an executor but that would be overkill for our driver which does very little work. |
|
The class of our driver that spark will execute. |
| Geocoding Jar | |
|
The jar that contains the class declared above. |
|
Configuration paths needed for geocoding. These paths were configured during the bootstrap phase of he cluster starting up. |
| Geocoding Options | |
|
The format and path to the input data and the fields to be used for geocoding. |
|
The path to save the output and the desired geocode fields that will be added, along with an error field containing error messages if present. |
|
Our cluster will have 47 4-core Executors which means it can work on 47 * 4 = 188 tasks at once. By default Spark will split this data by the Executor Count, 47. To fully utilize our cluster we have to force our data into 188 partitions. See Part 2 for more details. |
Full Execution
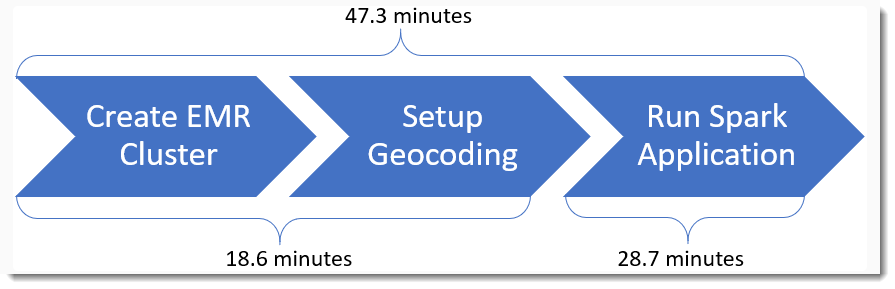
Now that we know the cluster specifications, have the scripts to setup geocoding, and know our spark-submit command then we can execute the process.
This will geocode the 19 million addresses and save a table that has the following structure:
| id | address1 | address2 | address3 | city | state/province | postal code | country | x | y | pb_key | error |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 350 Jordan Road | Troy | NY | 12180 | USA | -73.700257 | 42.678161 | P0000GL638OL | |||
| ... | |||||||||||
| 19385996 | 35 Railroad Row | Unit 1 | White River Junction | VT | 05001 | USA | -72.318588 | 43.649212 | P0000N0KF8X7 | ||
Performance Analysis
We are going to analyze the time spent in the Spark Application step of our process.
Total Time Spent Geocoding: 28.7 minutes
Geocodes per second (Across entire cluster): 11257.8
Geocodes per second per core: 59.88
Using Geocodes per second per core we can calculate how long our Spark Application would take if had more, or less, worker nodes. For example, if we only had 1 worker node then our Spark Executors would only have 44 cores to utilize and the job would take 2 hours and 3 minutes. If we had 10 worker nodes then the cluster would have 476 for our Spark Executors and the job would only take 11.3 minutes. The time spent creating the cluster and setting up geocoding is constant in all scenarios, which means adding more nodes becomes marginally beneficial.
 © 2019, 2021 Precisely. All rights
reserved.
© 2019, 2021 Precisely. All rights
reserved.
|
Precisely.com |