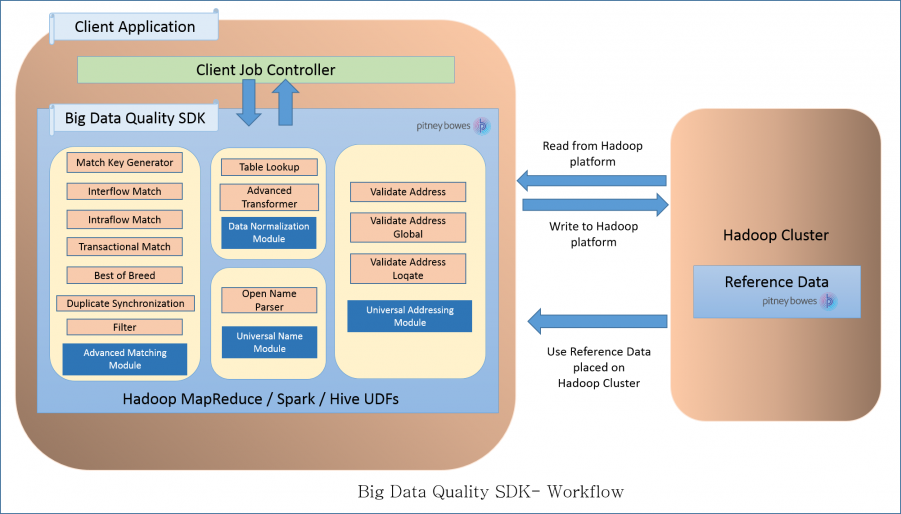
Workflow
To use the SDK, the components required are:
- Big Data Quality SDK Installation
- The Big Data Quality SDK JAR file must be installed on your system and available for use by your application.
- Client Application
- The Java application you must create to invoke and run the required Data Quality operations using the SDK. The Big Data Quality SDK JAR file must be imported into your Java application.
- Hadoop Platform
- On running a job using the Big Data Quality SDK, data is first read from the
configured Hadoop platform, and after the relevant processing, the output data is
written to the Hadoop platform.
For this, the access details of the Hadoop platform must be configured correctly in your machine. For more information, see Overview.
- Reference Data
- The Reference Data, required by the Big Data Quality SDK, is placed on the
Hadoop cluster.
- Java API
-
To use the Java API, you can opt to place the reference data on either of the below:
- Local Data Nodes: The Reference Data is placed on all available
data nodes in the cluster.Note: This is not a failsafe method.
- Hadoop Distributed File System (HDFS): The Reference Data is placed on an HDFS directory. This ensures your data is failsafe.
- Local Data Nodes: The Reference Data is placed on all available
data nodes in the cluster.
- Hive UDFs
- To use the Hive UDFs, you must place the reference data on each local data node of the cluster.
Note: The SDK also enables Distributed Caching for enhanced performance.