Flat Sample
Configuring Read from File
The Write to Hub dataflow that uses a flat file for input looks like this:
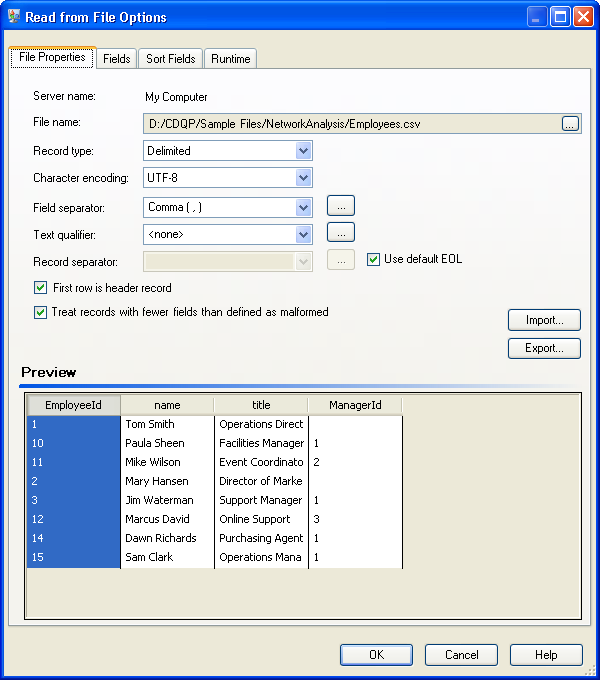
- Employee ID
- Name
- Title
- Manager ID

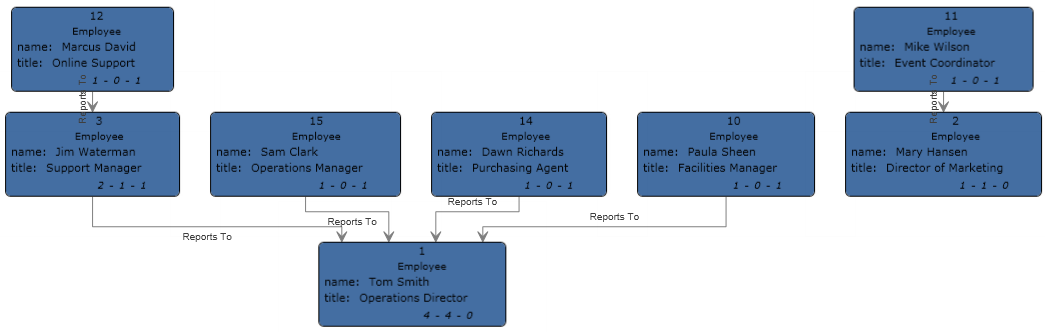
Notice that two employees do not have manager IDs. These employees (Tom Smith and Mary Hansen) are both directors and therefore have no manager in this exercise. All other employees have a number in the ManagerID field that refers to the employee who is their manager. For example, Paula Sheen's record has "1" in the ManagerID field, indicating that Tom Smith is her manager.
The Read from File stage appears as follows when it is configured to work with this input file:
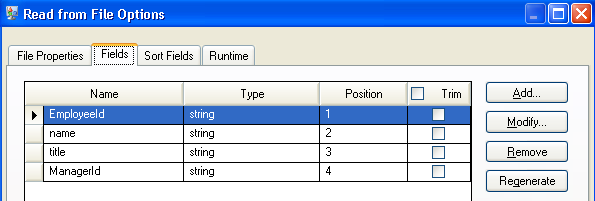
Next we configure the Write to Hub stage. After naming the model "Employees" we configure the stage to include the entities and relationships that will comprise the model.
Because we are creating a model that is similar to an organization chart, our entities are employees who are assigned numeric IDs. The first thing we do on the Add Entity dialog box is click the browse button to access the Field Schema dialog box, and then select "EmployeeId" from the list of available fields. This is the first group of entities in our model.
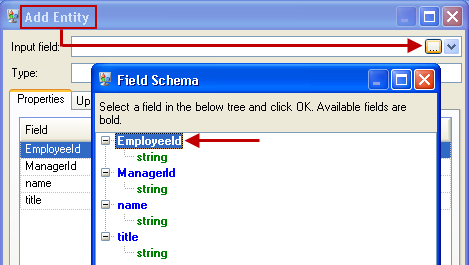
Next, we set the Type field to "Employee" and check the boxes for "name" and "title" because we want the information from those fields to be brought in as properties for the EmployeeID entities in the model.
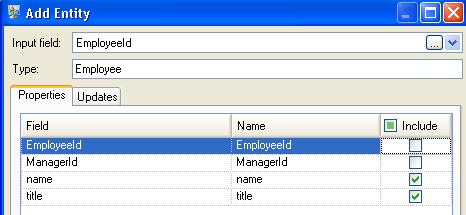
After setting properties for the Employee entity, we configure the processing options. The Updates tab enables you to specify whether properties can be updated in the model once they are in place and if they should overwrite existing data. For instance, in our example, Mary Hansen would be encountered twice because on record 4, she is referred to as an employee, but on record 3, she is referred to as a manager. When Write to Hub processes Mary for the second time, it could potentially overwrite or remove data that was populated as a result of the first time it processed Mary. By selecting Never overwrite properties with empty data (which is the default), any updates that occur will create new properties and overwrite existing properties, but they will not blank out properties that were set by the first encounter but missing in the second encounter. This also ensures that the order in which these records are read has no impact on the model.
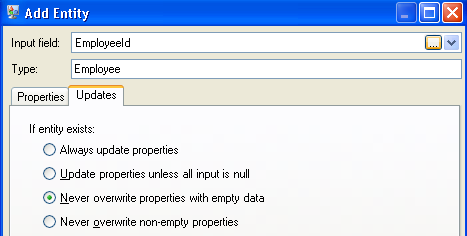
If we selected Always update properties, data would always be overwritten and only the last set of property data would be reflected in the model. If we selected Update properties unless all input is null, data would always be overwritten unless every field in the new record were blank. Finally, if we selected Never overwrite non-empty properties, the first set of data for any given field would be retained, unless that field were blank. In that case, the first set of non-blank data would be retained.
We repeat these steps to add "ManagerId" as the second group of entities in our model. Although ManagerID and EmployeeID are different fields in the input file, both entities' types are set to “Employee.” If we set ManagerID to a different type, the model would contain two entities for mid-level managers. For example, Jim Waterman would have an entity as an employee and an entity as a manager. With both entities being set to "Employee" as the type, mid-level managers such as Jim will have just one entity in the model. That entity will have other entities coming into it (from employees) and another entity going out of it (to their respective manager). Note that we do not add properties to the ManagerID entities because the values in those fields (name, title) apply to the employees, not the managers. Also, we accept the Never overwrite properties with empty data default selection on the Updates tab.
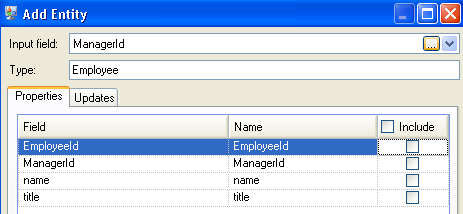
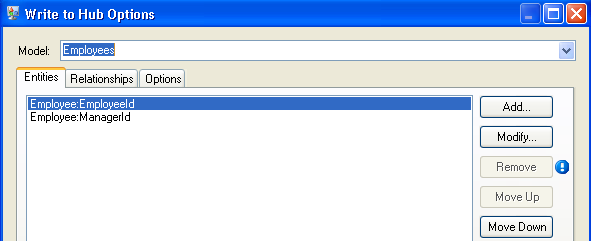
The completed Entities tab for this example appears as follows:
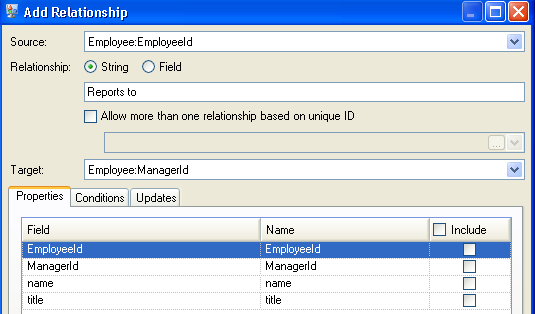
Now we configure the Relationships tab. The first thing we do on the Add Relationship dialog box is select the source of the relationship from the list of entities created on the Entities tab. The relationship between our entities reflects the reporting structure (employee to manager); therefore, we select the "Employee:EmployeeID" entity as the source. Next, we select "String" as name of the relationship, and we enter the text "Reports to." After that, we select the target of the relationship from the list of the entities created on the Entities tab; for our example, we select "Employee:ManagerID." If we were using a "manages" relationship instead of a "reports to" relationship, we would reverse the selections in the source and target fields.
The completed Relationships tab for this example appears as follows:
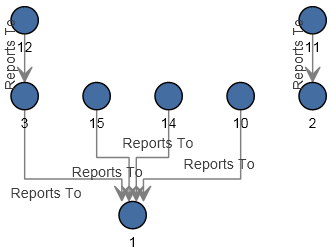
The configuration of this dataflow is complete and results in the following model, as depicted in the Relationship Analysis Client. This example uses the Hierarchic layout with default settings for entities.
Another way to view this same data is with Panel style, as shown below. The benefit of using Panel style is that you can see the properties associated with each entity.