Configuration d'instances d'exécution locales
Chaque stage dans un flux de données fonctionne de manière asynchrone dans son propre thread et est indépendant de tout autre stage. Ceci permet le traitement parallèle des stages dans un flux de données, ce qui vous permet d'utiliser plus d'une instance d'exécution pour un stage. Ceci s'avère utile dans les flux de données dans lesquels certains stages traitent les données plus vite que d'autres. Cela peut mener à une distribution non équilibrée du travail parmi les threads. Par exemple, prenons un flux de données composé des stages suivants :

Selon la configuration de ces stages, il est possible que le stage Validate Address traite les enregistrements plus vite que le stage Geocode US Address. Si tel est le cas, à un certain moment de l'exécution du flux de données, tous les enregistrements auront été traités par Validate Address, mais Geocode US Address aura encore des enregistrements à traiter. Afin d'améliorer la performance de ce flux de données, il est nécessaire d'améliorer la performance du stage qui est le plus lent - dans notre cas, Geocode US Address. Une manière d'accomplir cela est de spécifier plusieurs instances d'exécution du stage. Régler le nombre d'instances d'exécution sur deux, par exemple, signifie qu'il y aura deux instances de ce stage, chacune s'exécutant dans son propre thread, disponible pour le traitement de vos enregistrements.
La procédure suivante explique comment définir un stage pour qu'il utilise plusieurs instances d'exécution.
-
Cliquez sur Exécution.
Par exemple, voici le bouton Exécution du stage Geocode US Address.
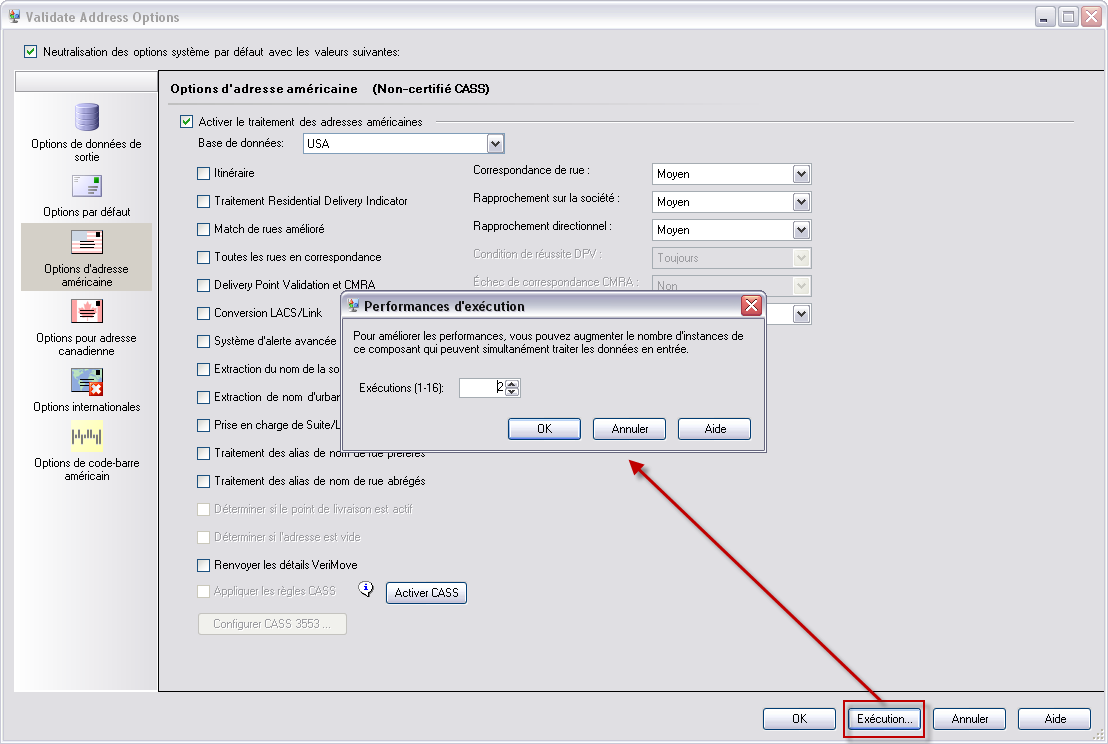 Remarque : Tous les stages ne sont pas capables d'utiliser plusieurs instances d'exécution. Si aucun bouton Exécution n'apparaît au bas de la fenêtre du stage, cela signifie que le stage n'est pas capable d'utiliser plusieurs instances d'exécution.
Remarque : Tous les stages ne sont pas capables d'utiliser plusieurs instances d'exécution. Si aucun bouton Exécution n'apparaît au bas de la fenêtre du stage, cela signifie que le stage n'est pas capable d'utiliser plusieurs instances d'exécution.