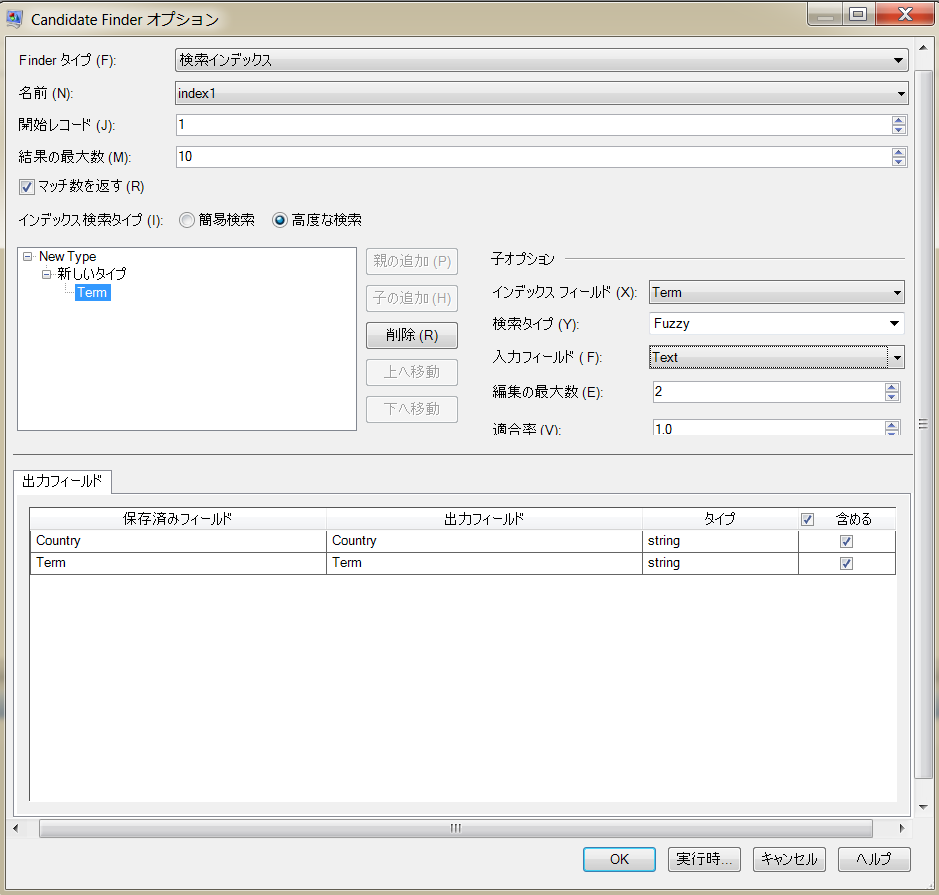
高度な検索インデックス オプション
|
オプション名 |
説明 / 有効な値 |
|---|---|
|
Finder タイプ |
検索インデックスを選択します。 |
|
名前 |
Enterprise Designer の Advanced Matching 展開済みステージの下で Write to Search Index ステージを使用して作成された適切なインデックスを選択します。 |
|
開始レコード |
検索結果の最初のレコード番号を入力します。デフォルト値は 1 です。 |
|
結果の最大数 |
インデックス検索で返す応答の最大数を入力します。デフォルトは 10 です。 |
|
マッチ数を返す |
マッチ総数を返します。例えば、上の [結果の最大数] フィールドをデフォルトの "10" のままにしている場合、結果は 10 件しか返されません。しかし、このチェック ボックスをオンにすれば、処理中に得られたマッチ総数が出力フィールド TotalMatchCount に返されます。 |
| インデックス検索タイプ | 実行するインデックス検索のタイプを決定します。[高度な検索] を選択します。 |
|
[親の追加] ボタン |
親オプションにアクセスします。 |
|
親オプション — 名前 |
親の名前を入力します。 |
|
親オプション — 検索方法 |
親がマッチかどうかを判定する方法を指定します。次のいずれかです。 すべて真 — すべての子がマッチと判定される場合、親はマッチと見なされます。この方法を選択すると、子の間に "AND" コネクタが作成されます。 いずれかが真 — 少なくとも 1 つの子がマッチと判定される場合、親はマッチと見なされます。この方法を選択すると、子の間に "OR" コネクタが作成されます。 いずれも真でない — いずれの子もマッチと判定されない場合、親はマッチと見なされます。この方法を選択すると、子の間に "NOT" コネクタが作成されます。 |
|
[子の追加] ボタン |
子オプションにアクセスします。 |
|
子オプション — インデックス フィールド |
検索インデックスを作成するフィールドを選択します。 |
|
子オプション — 検索タイプ |
入力データを検索するか、インデックス データと照合するかを判定する検索/マッチング条件を指定します。検索では大文字と小文字がすべて区別されます。 |
| 語または句が次で始まる | 検索インデックス フィールドに含まれるテキストが、入力フィールドに含まれるテキストで始まるかどうかを判定します。 例えば、入力フィールド内のテキスト "tech" は、"Technical"、"Technology"、"Technologies"、"Technician"、"National University of Technical Sciences" などを含む検索インデックス フィールドとのマッチと見なされます。同様に、入力フィールド内の語句 "DEF Sof" は、"ABC DEF Software"、"DEF Software"、および "DEF Software India" を含む検索インデックス フィールドとのマッチと見なされますが、"Software DEF" や "DEF ABC Software" を含む検索インデックス フィールドとのマッチとは見なされません。 |
| 含む | 検索インデックス フィールドに入力フィールドのデータが含まれるかどうかを判定します。この検索タイプでは、検索インデックス フィールドを検索するときに入力フィールドの単語の並びを考慮します。例えば、入力フィールドのデータが "Pitney" と "Pitney Bowes" の場合、これらの単語は検索インデックス フィールド "Pitney Bowes Software Inc." に含まれていると見なされます。 |
| すべて含む | 入力フィールドの英数字がすべて検索インデックス フィールドに含まれているかどうかを判定します。この検索タイプでは、検索インデックス フィールドを検索するときに入力フィールドの単語の並びを考慮しません。 |
| いずれかを含む | 入力フィールドのいずれかの英数字が検索インデックス フィールドに含まれているかどうかを判定します。 |
| いずれも含まない | 入力フィールドの英数字から成る単語がいずれも検索インデックス フィールドに含まれていないかどうかを判定します。 |
| あいまい | ある単語を別の単語に変換するために必要な削除、挿入、または置換の数に基づいて、英数字から成る 2 つの単語間の類似性を判断します。 [編集の最大数] パラメータを使用して、正しいマッチと見なすために許容する編集回数の制限を設定します。
[あいまい] 検索タイプは、1 つの単語の検索でのみ使用されます。[余分な単語を無視] をクリックすると、Candidate Finder は、入力フィールドとインデックス フィールドを比較するときに、フィールド内の最初の単語のみを考慮します。例えば、インデックス フィールドが "Pitney"、入力フィールドが "Pitney Bowes" の場合、これらのフィールドは "Bowes" のある/なしによってマッチと見なされません。ただし、このボックスをオンにすると、"Bowes" は無視され、最初の単語である "Pitney" のみが考慮されるため、2 つの単語はマッチと見なされます。 |
| 数値 | 入力フィールドの数字がすべて検索インデックス フィールドに含まれているかどうかを判定します。 [数値] 検索タイプは、1 つの単語の検索でのみ使用されます。 [余分な単語を無視] をクリックすると、Candidate Finder は、入力フィールドとインデックス フィールドを比較するときに、フィールド内の最初の単語のみを考慮します。 |
| パターン | 入力フィールドのテキスト パターンが検索条件のテキスト パターンと一致しているかどうかを判定します。さらに、[パターン文字列] フィールドで、テキスト パターンを変更できます。例えば、入力フィールドに "nlm" が含まれ、定義されているパターンが "a*b?c" の場合、この入力フィールドは、"Neelam"、"nelam"、"neelum"、"nilam" などの単語と一致します。 [パターン] 検索タイプは、1 つの単語の検索でのみ使用されます。[余分な単語を無視] をクリックすると、Candidate Finder は、入力フィールドとインデックス フィールドを比較するときに、フィールド内の最初の単語のみを考慮します。 |
| 近接度 | 入力フィールド内の各単語が一定の距離内にあるかどうかを判定します。
例えば、この検索タイプを正しく使用すると、"Spectrum Technology Platform is a product of Pitney Bowes Software Inc." という文章を含む検索インデックス フィールドから互いに 10 単語以内の距離で "Spectrum" ([入力フィールド 1 ] の単語) と "Pitney" ([入力フィールド 2 ] の単語) を検索できます。 [直線距離] 検索タイプは、1 つの単語の検索でのみ使用されます。[余分な単語を無視] をクリックすると、Candidate Finder は、入力フィールドとインデックス フィールドを比較するときに、フィールド内の最初の単語のみを考慮します。 |
| 範囲 | ある範囲内に含まれる語の包含的検索を実行します。範囲の指定には、下限フィールド (開始語) と上限フィールド (終了語) を使用します。検索インデックス フィールド内では、英数字から成るすべての単語は辞書の順序で配列されます。
例えば、20001 ([下限フィールド] で定義) ~ 20009 ([上限フィールド] で定義) までの郵便番号を検索すると、その範囲内の郵便番号を持つ住所がすべて返されます。 [範囲] 検索タイプは、1 つの単語の検索でのみ使用されます。[余分な単語を無視] をクリックすると、Candidate Finder は、入力フィールドとインデックス フィールドを比較するときに、フィールド内の最初の単語のみを考慮します。 |
| ワイルドカード | 1 つ以上のワイルドカード文字を使用して検索します。 ワイルドカード文字を挿入する入力ファイル内での [位置] を選択します。 [ワイルドカード] 検索タイプは、1 つの単語の検索でのみ使用されます。[余分な単語を無視] をクリックすると、Candidate Finder は、入力フィールドとインデックス フィールドを比較するときに、フィールド内の最初の単語のみを考慮します。 |
|
子オプション — 適合率 |
最大 100 までの数字を入力して、子フィールドの適合率を制御します。ブースト係数を高くすると、フィールドの適合性が高まります。例えば、[企業名] フィールドからの結果の適合性を他のフィールドからの結果の適合性よりも高くする場合は、[インデックス フィールド名] から "企業名" を選択し、"5" を入力します。
注: ここで入力する数字は正の数でなければなりませんが、1 未満の数字、例えば "0.5" なら有効です。
|
|
空白を無視 |
クエリで、空の入力ファイル フィールドを考慮する場合は、このチェックボックスをオフにします。
注: デフォルトでは、クエリによって空のフィールドが無視されます。
|
|
[出力フィールド] タブ |
[含める] ボックスをオンにすると、出力に含める必要がある保存済みフィールドを選択できます。
注: 入力フィールドがデータフローの以前のステージのもので、検索インデックスの保存フィールド名と同じ名前を持つ場合、入力フィールドの値によって出力フィールドの値は上書きされます。
|
- 検索インデックスの [名前] は "CF_Index"
- [開始レコード] は 26 で、検索結果は 26 番目のレコードから開始
- [結果の最大数] は 10 で、結果は 10 件しか返されない
- [合計マッチ数を返す] のオプションが選択されており、これには表示上限の 10 件だけでなくすべてのレコードが含まれる
- 高度なインデックス検索タイプ
- 親タイプ名 "State Match"
- 子タイプ名 "StateProvince" (インデックス フィールド名に基づく)
- [あいまい] 検索タイプで [編集の最大数] を 2 に設定 (編集回数が最大 2 回であれば正しいマッチと見なす)
- [入力フィールド] "StateProvince" を [インデックス フィールド] "StateProvince" の照合対象として使用
- 州データの適合性を高めるために [適合率] を 2.0 に設定
- InputKeyValue、AddressLine1、AddressLine2、StateProvince および PostalCode フィールドが出力に返されるが、FirmName または City フィールドは返されないことを示すフィールド マップ