この手順では、Interflow Match ステージを使用して、あるソースに含まれるレコードが別のソースのレコードにマッチするかどうかを特定する方法を説明します。第 1 のソースにはサスペクト レコードが含まれ、第 2 のソースには候補レコードが含まれます。このデータフローでは、レコードは別のソースのレコードにのみマッチングします。同じソース内でレコードがマッチングするかは確認されません。このデータフローは、レコードを一致するレコードのコレクションにグループ化し、そのコレクションを出力ファイルに書き込みます。
-
Enterprise Designer で、新しいデータフローを作成します。
-
2 つのソース ステージをキャンバスにドラッグします。1 つのステージはサスペクト レコードのソースを参照するように設定し、もう 1 つのステージは候補レコードのソースを参照するように設定します。
ソース ステージの設定手順については、『データフロー デザイナー ガイド』を参照してください。
-
Match Key Generator ステージをキャンバスにドラッグし、ソース ステージの 1 つに接続します。
例えば、Read from File ソース ステージを使用している場合は、データフローは次のようになります。
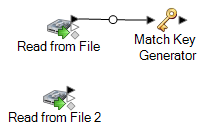
Match Key Generator は、レコードごとに非ユニーク キーを作成します。この非ユニーク キーは、潜在的な重複レコードのグループを特定するためにマッチング ステージで使用できます。 マッチ キーを使用すると、レコードをマッチ キー別にグループ化し、各グループ内でのみレコードを比較できるので、マッチング プロセスが促進されます。
注: 2 番目の Match Key Generator ステージは後で追加します。この段階では、キャンバスに必要なステージは 1 つだけです。
-
Match Key Generator ステージをダブルクリックします。
-
[追加] をクリックします。
-
各レコードのマッチ キーを生成するために使用するルールを定義します。
表 1. Match Key Generator のオプション
|
オプション名
|
説明 / 有効な値
|
|
アルゴリズム
|
マッチ キーの生成に使用するアルゴリズムを指定します。次のいずれかです。
- Consonant (子音)
- 指定されたフィールドを、子音を削除して返します。
- Double Metaphone
- 文字の発音表記に基づくコードを返します。Double Metaphone は Metaphone アルゴリズムの改良版で、さまざまな言語に多数存在する不規則性を考慮しています。
- Koeln
- ドイツ語で発音される名前に、音声によってインデックスを付けます。同じ発音を持つ名前を同じ表現にエンコードできるので、綴りに小さな相違があっても、マッチさせることができます。結果は常に一連の数字です。特殊文字および空白は無視されます。このオプションは、Soundex の制限に対応するために作成されました。
- MD5
- 128 ビットのハッシュ値を生成するメッセージ ダイジェスト アルゴリズム。このアルゴリズムは、データの一貫性の確認によく使用されます。
- Metaphone
- 選択したフィールドを Metaphone コード化したキーを返します。Metaphone は、英語の発音を使用して単語をコード化するアルゴリズムです。
- Metaphone (スペイン語)
- 選択したフィールドをスペイン語用に Metaphone コード化したキーを返します。この Metaphone アルゴリズムは、スペイン語の発音を使用して単語をコード化します。
- Metaphone 3
- Metaphone アルゴリズムおよび Double Metaphone アルゴリズムを、より正確な子音および内部母音の設定で改良したもので、単語または名前の一致性を高く、または低くして、音声ベースで語を検索できるようにします。Metaphone 3 では、音声エンコーディングの精度が 98% に向上しています。このオプションは、Soundex の制限に対応するために作成されました。
- Nysiis
- 近似の発音と正確な綴りをマッチさせ、同じように発音される単語にインデックスを付ける、音声コード アルゴリズム。New York State Identification and Intelligence System の一部です。例えば、住民のデータベースで誰かの情報を探しているとします。その人物の名前は "John Smith" のように聞こえますが、実際の綴りは "Jon Smyth" です。"John Smith" の完全一致を探す検索を実行した場合、返される結果はありません。しかし、NYSIIS アルゴリズムを使用してデータベースにインデックスを作成し、再度 NYSIIS アルゴリズムを使用して検索した場合は、正しいマッチが返されます。なぜなら、"John Smith" と "Jon Smyth" は、このアルゴリズムによってどちらも "JAN SNATH" というインデックスが付けられているからです。
- Phonix
- 100 を越える変換ルールを適用することによって、名前文字列を単一の文字またはいくつかの文字のシーケンスに前処理します。これらのルールのうち 19 個は文字がその文字列の先頭にある場合にのみ適用され、12 個はその文字列の中間にある場合にのみ適用され、28 個は文字列の終わりにある場合にのみ適用されます。変換された名前文字列は、開始文字とそれに続く 3 桁 (ゼロおよび重複する数字を削除) で構成されるコードにエンコードされます。このオプションは、Soundex の制限に対応するために作成されました。このオプションは複雑なため、Soundex より遅くなります。
- Soundex
- 選択したフィールドの Soundex コードを返します。Soundex は、単語の英語の発音に基づいて、固定長のコードを生成します。
- 部分文字列
- 選択されているフィールドの指定部分を返します。
|
|
フィールド名
|
選択したアルゴリズムを適用してマッチ キーを生成するフィールドを指定します。例えば、LastName というフィールドを選択し、Soundex アルゴリズムを選択した場合、Soundex アルゴリズムが LastName フィールドのデータに適用されて、マッチ キーが生成されます。
|
|
開始位置
|
指定したフィールド内での開始位置を指定します。すべてのアルゴリズムで開始位置を指定できるとは限りません。
|
|
長さ
|
開始位置から含める文字の数を指定します。すべてのアルゴリズムで長さを指定できるとは限りません。
|
|
ノイズ文字の削除
|
ハイフン、空白、その他の特殊文字等、英数字以外の文字を入力フィールドからすべて削除します。
|
|
ソート入力
|
入力フィールド内の文字または語をすべてアルファベット順にソートします。
- 文字
- ユニーク ID を作成する前に、入力フィールドの文字値をソートします。
- 語
- ユニーク ID を作成する前に、入力フィールドの各語値をソートします。
|
-
ルールの定義が終了したら、[OK] をクリックします。
-
キャンバスで Match Key Generator ステージを右クリックして、[ステージのコピー] を選択します。
-
キャンバスの空いている領域を右クリックし、[貼り付け] を選択します。
-
Match Key Generator のコピーを他のソース ステージに接続します。
例えば、Read from File 入力ステージを使用している場合は、データフローは次のようになります。
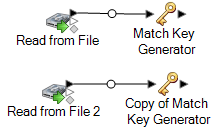
データフローには、まったく同じルールを使用して各ソースのマッチ キーを生成する 2 つの Match Key Generator ステージが含まれるようになりました。このデータフローが正しく機能するには、同じ設定の Match Key Generator ステージを用意することが不可欠です。
-
Interflow Match ステージをキャンバスにドラッグし、各 Match Key Generator ステージをそれに接続します。
例えば、Read from File 入力ステージを使用している場合は、データフローは次のようになります。
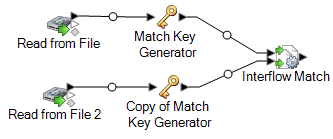
-
Interflow Match ステージをダブルクリックします。
-
[ロードするマッチ ルール] フィールドで、定義済みのいずれかのマッチ ルールを選択します。このマッチ ルールはそのまま使用することも、必要に応じて変更することもできます。 定義済みのいずれかのマッチ ルールを出発点として使用せずに、新しいマッチ ルールを作成する場合は、[新規作成] をクリックします。 カスタム ルールは、データフローで 1 つだけ使用できます。
注: Enterprise Designer の [データフロー オプション] 機能を使用すると、マッチ ルールを実行時に公開して設定できます。
-
[グループ化] フィールドで、[マッチ キー] を選択します。
同じマッチ キーを持つレコードがグループに配置されます。マッチ ルールがグループ内のレコードに適用されて、重複があるかどうかが確認されます。各レコードのマッチ キーは、この手順で先に設定した Generate Match Key ステージによって生成されます。
-
他のオプションの変更の詳細については、マッチ ルールの作成を参照してください。
-
シンク ステージをキャンバスにドラッグし、Interflow Match ステージに接続します。
例えば、Write to File シンク ステージを使用した場合、データフローは次のようになります。
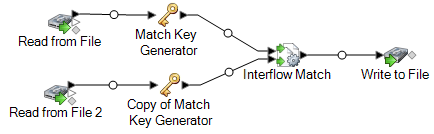
-
シンク ステージをダブルクリックして設定します。
シンク ステージの設定方法については、『データフロー デザイナー ガイド』を参照してください。
2 つのデータ ソースのレコードをマッチングするデータフローが完成しました。
複数のソースからのレコードのマッチングの例
ダイレクト メールの会社で、メール拒否リストに載っているユーザを識別してダイレクト メールが送信されないようにします。1 つのファイルには受取人のリストがあり、もう 1 つのファイル (禁止ファイル) にはダイレクト マーケティング メールの受け取りを拒否している人のリストがあります。
以下のデータフローは、このビジネス シナリオの解決策を示しています。
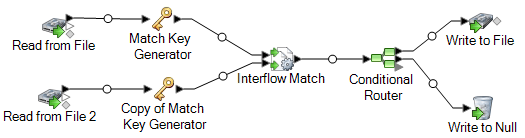
Read from File ステージでメーリング リストからデータを読み込み、Read from File 2 ステージで禁止リストからデータを読み込みます。2 つの Match Key Generator ステージはまったく同じ設定なので、これらによって生成されるマッチ キーを Interflow Match で使用して、一致する可能性のあるグループを作成できます。Interflow Match はメーリング リストと禁止ファイルの両方にあるレコードを識別し、これらのレコードを重複としてマークします。Conditional Router は、ユニーク レコード (禁止リストで見つからなかったレコード) を Write to File に送信し、ファイルに書き込みます。Conditional Router ステージは他のすべてのレコードを Write to Null に送信して破棄します。