iemodel evaluate model
iemodel evaluateコマンドは、Information Extraction モジュールのトレーニング済みモデルを評価します。
使用方法
iemodel evaluate model--nmodelName--ttestFileName--ooutputFileName--ccategoryCount--dtrueOrfalse| 必須 | 引数 | 説明 |
|---|---|---|
| はい | --n modelName | 評価するモデルの名前と場所を指定します。ここでは、管理ユーティリティを実行しているディレクトリへの相対パスを使用します。 |
| はい | --t testFileName | モデルの評価に使用するテスト ファイルの名前と場所を指定します。 |
| いいえ | --o outputFileName | 評価結果を格納する出力ファイルの名前と場所を指定します。 |
| いいえ | --c categoryCount | モデル内のカテゴリ数を指定します。数値を指定する必要があります。 注: テキスト分類モデルのみに適用されます。
|
| いいえ | --d trueOrfalse | テーブルをエンティティに関する詳細分析とともに表示するかどうか指定します。値は次の trueまたは false にする必要があります。
falseです。 モデル評価の結果テーブルと、その列を示す混同行列には、以下に示すように、エンティティごとのカウントが表示されます。 注: この引数を指定しないか、この引数の値を false に指定してコマンドを実行すると、モデル評価の結果テーブルと混同行列は表示されません。モデル評価の統計値のみが表示されます。
|
出力
- モデル評価の統計値
- このコマンドを実行すると、テーブル形式で以下の評価の統計情報が表示されます。
- 適合率: 厳密性を示す指標です。適合率は、正しく識別された組の割合を示します。
- 再現率: 結果の完全性を示す指標です。再現率は、関連するインスタンスのうち、検出されたインスタンスの比率として定義できます。
- F1 値: テストの正確性を示す指標です。F1 スコアの計算では、テストの適合率と再現率の両方が考慮されます。これは適合率と再現率の加重平均として解釈でき、F1 スコアの最高値は 1、最低値は 0 になります。
- 正確度: 結果の正確性を示す指標です。これは測定値と既知値の近さを示します。
- モデル評価の結果
- コマンドを引数
--d trueを指定して実行すると、すべてのエンティティのマッチ数がテーブル形式で表示されます。そのテーブルには次の列があります。- Input Count (入力数)
- 入力データ内のエンティティの発生数。
- Mismatch Count (不一致数)
- エンティティのマッチが失敗した回数。
- Match Count (マッチ数)
- エンティティのマッチに成功した回数。
- 混同行列
- 混同行列 (以下を参照) では、アルゴリズムの性能を視覚化できます。分類モデルの性能を示します。
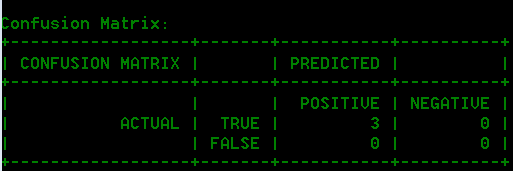
例
この例の内容は次のとおりです。
iemodel evaluate model --n MyModel --t C:\Spectrum\IEModels\ModelTestFile --o C:\Spectrum\IEModels\MyModelTestOutput --c 4 --d true- "MyModel" というモデルを評価
- 同じ場所にある "ModelTestFile" というテスト ファイルを使用
- "MyModelTestOutput" というファイルに評価の出力を格納
- カテゴリ数は 4
- 評価の詳細分析は必須