Archivo Read From HL7
La etapa Read from HL7 File lee datos de Health Level Seven (HL7) desde un archivo de texto como entrada a un flujo de datos. HL7 es un estándar de mensajería que se utiliza en la industria de la salud para el intercambio de datos entre sistemas. Para obtener más información acerca de HL7, vaya a www.hl7.org.
Formato de mensaje HL7
Los datos de un mensaje HL7 se organizan jerárquicamente de la siguiente manera:
- mensaje
- segmento
- campo
- componente
- Subcomponente
- componente
- campo
- segmento
Cada una de las líneas de un mensaje HL7 es un segmento. Un segmento es una agrupación lógica de campos. Los primeros tres caracteres en un segmento identifican el tipo de segmento. En el mensaje anterior, hay cinco segmentos MSH (encabezado del mensaje), PID (identificación de paciente), dos segmentos NK1 (familiares) y IN1 (seguro).
Cada segmento está formado por una serie de campos. Un campo contiene información relacionada con el objetivo del segmento, como el nombre de la compañía de seguros en el segmento IN1 (seguro). Los campos normalmente (pero no siempre) están delimitados por un carácter |.
Los campos se pueden dividir en componentes. Normalmente, los componentes se indican con un carácter ^. En el ejemplo anterior, el segmento PID (identificación del paciente) contiene un campo de nombre del paciente con LEVERKUHN^ADRIAN^C que tiene tres partes, el apellido (LEVERKUHN), el nombre (ADRIAN) y la inicial del segundo nombre (C). Los componentes se pueden dividir en subcomponentes. Normalmente, los subcomponentes se indican con un carácter &.
El siguiente es un ejemplo de un mensaje HL7:
MSH|^~\&||.|||199908180016||ADT^A04|ADT.1.1698593|P|2.7
PID|1||000395122||LEVERKUHN^ADRIAN^C||19880517180606|M|||6 66TH AVE NE^^WEIMAR^DL^98052||(157)983-3296|||S||12354768|87654321
NK1|1|TALLIS^THOMAS^C|GRANDFATHER|12914 SPEM ST^^ALIUM^IN^98052|(157)883-6176
NK1|2|WEBERN^ANTON|SON|12 STRASSE MUSIK^^VIENNA^AUS^11212|(123)456-7890
IN1|1|PRE2||LIFE PRUDENT BUYER|PO BOX 23523^WELLINGTON^ON^98111|||19601||||||||THOMAS^JAMES^M|F|||||||||||||||||||ZKA535529776- Copie y pegue el texto de muestra en un documento nuevo por medio de cualquier software para la edición de texto, como Notepad++.
- Realice los cambios de contenido que sean necesarios.
- Configure para ver el final de línea (EOL) en el texto. En Notepad++, vaya a .
- Cambie el formato de conversión de final de línea a
CR(retorno de carro). En Notepad++, vaya a . - Guarde el archivo HL7 después de realizar este cambio de formato.
Ficha Propiedades del archivo
|
Nombre de campo |
Descripción |
|---|---|
|
Server name (Nombre de servidor) |
Indica si el archivo que seleccionó como entrada está ubicado en la computadora que está ejecutando Enterprise Designer o en el servidor de Spectrum™ Technology Platform. Si selecciona un archivo en la computadora local, el nombre del servidor será Mi computadora. Si selecciona un archivo que se encuentra en el servidor, el nombre del servidor será Spectrum™ Technology Platform. |
|
Nombre de archivo |
Especifica la ruta al archivo. Haga clic en el botón de los puntos suspensivos (...) para buscar el archivo que desea. Nota: Si el servidor de Spectrum™ Technology Platform está ejecutándose en Unix o Linux, recuerde que estas plataformas distinguen las mayúsculas de las minúsculas en los nombres de los archivos y las rutas.
|
|
Versión de HL7 |
La versión de HL7 estándar utilizada en el archivo especificado. Por ejemplo, "2.7 " significa que el archivo utiliza HL7 versión 2.7. La versión de HL7 se indica en el 12.º campo del segmento |
|
Character encoding (Codificación de caracteres) |
Codificación del archivo de texto. Seleccione uno de estos:
|
|
Validar |
Estas opciones especifican si se debe revisar el archivo para garantizar que se cumpla el estándar HL7 2.7. Si el mensaje en el archivo falla la validación, se trata como un registro malformado y entrarán en vigor las opciones de registro malformado especificadas para el trabajo (en Enterprise Designer, en ) o para el sistema (en Management Console).
|
|
Ignorar los elementos inesperados |
Seleccione estas opciones si desea permitir mensajes que contengan segmentos, campos, componentes y subcomponentes que no estén en la posición esperada. Las posiciones esperadas se definen en el HL7 estándar o, en el caso de tipos de mensajes predeterminados, en la herramienta Administración de esquema de HL7 en Enterprise Designer. Por ejemplo, considere el siguiente esquema de mensaje predeterminado:
Y estos datos: En este caso, el segmento Los mensajes que contienen elementos en posiciones inesperadas se tratarán como registros malformados y entrarán en vigor las opciones de registro malformado especificadas para el trabajo (en Enterprise Designer, en ) o para el sistema (en Management Console). De forma predeterminada, todas las opciones Ignorar elemento inesperado están habilitadas para permitir tantos registros como se pueda procesar con éxito.
|
Ficha Campos
En la ficha Campos se muestran los segmentos, campos, componentes y subcomponentes. Utilice la ficha Campos para seleccionar los datos que desea leer en el flujo de datos.
Los grupos de segmento, que son recolecciones de segmentos usados juntos para incluir una categoría de datos, se muestran con un sistema de numeración que muestra dónde aparece el grupo en el esquema del mensaje. Cada grupo de segmento recibe un rótulo "Group_n" donde "n" es un número que corresponde a la posición del grupo en el esquema del mensaje. Para ilustrar cómo funciona el sistema de numeración, consideres este ejemplo:
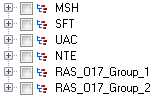
Este ejemplo muestra la lista de campo para el mensaje RAS^017. Este mensaje tiene dos grupos de segmento: RAS_017_Group_1 y RAS_017_Group_2. El grupo de segmento "Group_1" hace referencia al primer grupo de segmento en el esquema RAS^017 y el segundo grupo, "Group_2", hace referencia al segundo grupo indicado en el esquema RAS^017.
Para determinar qué grupo de segmento se representa con "Group_1" y "Group_2", encuentre la descripción del mensaje RAS^017 en el documento HL7 versión 2.7 estándar. Puede descargar una copia de este documento desde www.hl7.org.
En la descripción del mensaje, encuentre el primer grupo, el cual, en el caso de RAS^017, es el grupo PATIENT (Paciente). El segundo grupo en el esquema es el grupo ORDEN.
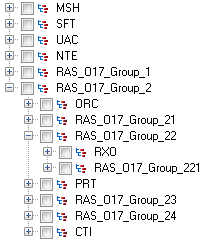
Los grupos de segmento que se anidan bajo un grupo de segmento tienen un número adicional adjunto a su número de grupo. Por ejemplo, el Group_21 representa el primer grupo anidado bajo el segundo grupo. Los posteriores subgrupos tienen números adicionales adjuntos a ellos, como Group_221, el cual, para el mensaje RAS^017, representa el grupo de segmento ORDER_DETAIL_SUPPLEMENT. A continuación se muestra un ejemplo de grupos anidados:
Los controles de la ficha Campos se describen en la siguiente tabla.
|
Nombre de la opción |
Descripción |
|---|---|
|
Regenerar |
Haga clic en este botón para rellenar la ficha Campos con una lista de todos los segmentos, campos, componentes y subcomponentes para el tipo de mensaje contenido en el archivo de entrada. Todos los elementos para el tipo de mensaje se mostrarán de acuerdo con el esquema HL7, independientemente de si el archivo de entrada contiene todos los elementos. Por ejemplo, si el archivo contiene un mensaje RAS, se mostrará el esquema del tipo de mensaje RAS completo independientemente de si el archivo de entrada contiene los datos de todos los segmentos, campos, componentes y subcomponentes. Si definió cualquier elemento personalizado con la herramienta Administración de esquema de HL7 en Enterprise Designer, aquellos elementos también se enumeran. |
|
Expandir todo |
Expande todos los elementos en la ficha campos para ver todos los segmentos, campos, componentes y subcomponentes de los tipos de mensaje incluidos en el archivo. |
|
Cerrar todo |
Cierra todos los nodos de la vista, de manera que se muestran solo los segmentos. Utilice esta opción para ver fácilmente los segmentos para los tipos de mensajes en el archivo. Después, puede ampliar cada uno de los segmentos con el fin de ver los campos, componentes y subcomponentes en un segmento. |
|
Seleccionar todo |
Marque esta casilla de verificación para crear campos de flujo de datos para todos los segmentos, campos, componentes y subcomponentes para todos los tipos de mensaje incluidos en el archivo. |