iemodel trainAndevaluate model
Der Befehl iemodel trainAndevaluate model wertet ein neues sowie ein vorhandenes Modell aus und trainiert dieses. Sie müssen ein vorhandenes Modell mit dem neu trainierten Modell überschreiben, indem Sie im Befehl „--u“ das Argument „true“ verwenden.
Dieser Befehl ruft Ihre Datei mit Trainingsoptionen auf und erstellt eine optionale Ausgabedatei mit Auswertungsergebnissen, sollten Sie sich für diese Option entscheiden.
Usage
iemodel trainAndevaluate model --f Trainingsoptionendatei --u WahrOderFalsch --o Ausgabedateiname --c Kategorieanzahl --d WahrOderFalsch| Erforderlich | Argument | Beschreibung |
|---|---|---|
| Ja | --f trainingOptionsFile | Gibt den Namen und den Speicherort der Datei mit den Trainingsoptionen an, die für das Training des Modells verwendet werden. Die hier von Ihnen angegebenen Verzeichnispfade sind relativ zu dem Speicherort, an dem Sie die Administrationsumgebung ausführen. |
| Nein | --u overWriteIfExists | Gibt an, ob das vorhandene trainierte Modell überschrieben werden soll (falls eins vorhanden ist).
|
| Nein | --o outputFileName | Gibt den Namen und den Speicherort der Ausgabedatei an, in der die Auswertungsergebnisse gespeichert werden. |
| Nein | --c categoryCount | Gibt die Anzahl an Kategorien in dem Modell an und muss ein numerischer Wert sein. Anmerkung: Gilt nur für das Textklassifizierungsmodell.
|
| Nein | --d trueOrfalse | Gibt an, ob eine Tabelle mit einer entitätsbezogenen detaillierten Analyse angezeigt werden soll. Der Wert muss true oder false sein, wie folgt:
false. In der Tabelle Ergebnisse der Modellauswertung und der Konfusionsmatrix mit den zugehörigen Spalten wird die Anzahl pro Entität angezeigt. Anmerkung: Wenn der Befehl ohne dieses Argument oder mit dem Argumentwert false ausgeführt wird, werden die Tabelle Ergebnisse der Modellauswertung und die Konfusionsmatrix nicht angezeigt. Nur die Statistik der Modellauswertung wird angezeigt.
|
Ausgabe
- Statistik der Modellauswertung
- Nach Ausführen dieses Befehls wird diese Auswertungsstatistik in tabellarischem Format angezeigt:
- Genauigkeit: Dies ist eine Maßeinheit für Genauigkeit. Die Genauigkeit definiert das Verhältnis ordnungsgemäß identifizierter Tupel.
- Wiederaufruf: Dies ist eine Maßeinheit für die Vollständigkeit der Ergebnisse. Der Wiederaufruf kann als Anteil relevanter Instanzen definiert werden, die abgerufen werden.
- F1-Wert: Dies ist die Maßeinheit für die Genauigkeit eines Tests. Bei der Berechnung des F1-Wertes werden die Genauigkeit und der Wiederaufruf des Tests berücksichtigt. Sie kann als gewichteter Mittelwert von der Genauigkeit und dem Wiederaufruf interpretiert werden, wobei das beste Ergebnis des F1-Wertes der Wert 1 und das schlechteste der Wert 0 ist.
- Genauigkeit: Misst bei den Ergebnissen den Grad der Korrektheit. Sie definiert die Nähe des gemessenen Wertes zu dem bekannten Wert.
- Ergebnisse der Modellauswertung
- Wenn der Befehl mit dem Argument
--d trueausgeführt wird, werden die Übereinstimmungsanzahlen aller Entitäten in tabellarischem Format angezeigt. Die Tabelle enthält folgende Spalten:- Anzahl Eingabe
- Die Häufigkeit der Vorkommen der Entität in den Eingabedaten.
- Anzahl Nichtübereinstimmungen
- Die Anzahl, wie oft der Entitätsvergleich keine Übereinstimmung ergab.
- Anzahl Übereinstimmungen
- Die Anzahl, wie oft der Entitätsvergleich eine Übereinstimmung ergab.
- Konfusionsmatrix
- Mit der Konfusionsmatrix (unten dargestellt) kann visualisiert werden, wie ein Algorithmus ausgeführt wird. Sie veranschaulicht die Leistung eines Klassifizierungsmodells.
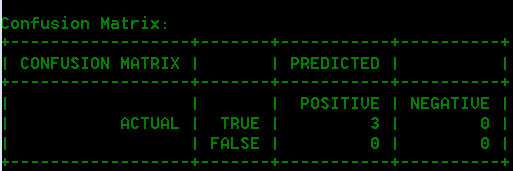
Beispiel
Beispiel:
iemodel evaluate train_model --f C:\Spectrum\IEModels\ModelTrainingFile --u true --o C:\Spectrum\IEModels\MyModelTestOutput --c 4 --d true- Verwendet eine Datei mit Trainingsoptionen namens „ModelTrainingFile“, die sich in „C:\Spectrum\IEModels“ befindet
- Überschreibt eine vorhandene Ausgabedatei mit demselben Namen
- Speichert die Ausgabe der Auswertung in einer Datei namens „MyModelTestOutput“
- Gibt eine Kategorieanzahl von 4 an
- Gibt an, dass eine detaillierte Analyse der Auswertung erforderlich ist