Globalen Verwenden eines globalen Caches für Abfragen
Wenn Sie über eine große Dimensionstabelle verfügen, können Sie die Daten der Dimensionstabelle in einen Cache laden und den Cache verwenden, um nach Surrogatschlüsseln zu suchen. Die Verwendung eines Cache verbessert die Leistung im Vergleich mit Suchvorgängen, die über Query DB direkt in der Dimensionstabelle durchgeführt werden.
Um einen Cache zu verwenden, müssen Sie zwei Datenflüsse erstellen: einen zum Füllen des Cache mit Dimensionstabellendaten und einen weiteren, der bei der Aktualisierung der Faktentabelle den Cache verwendet. Das folgende Diagramm zeigt, wie die beiden Datenflüsse zusammenarbeiten:
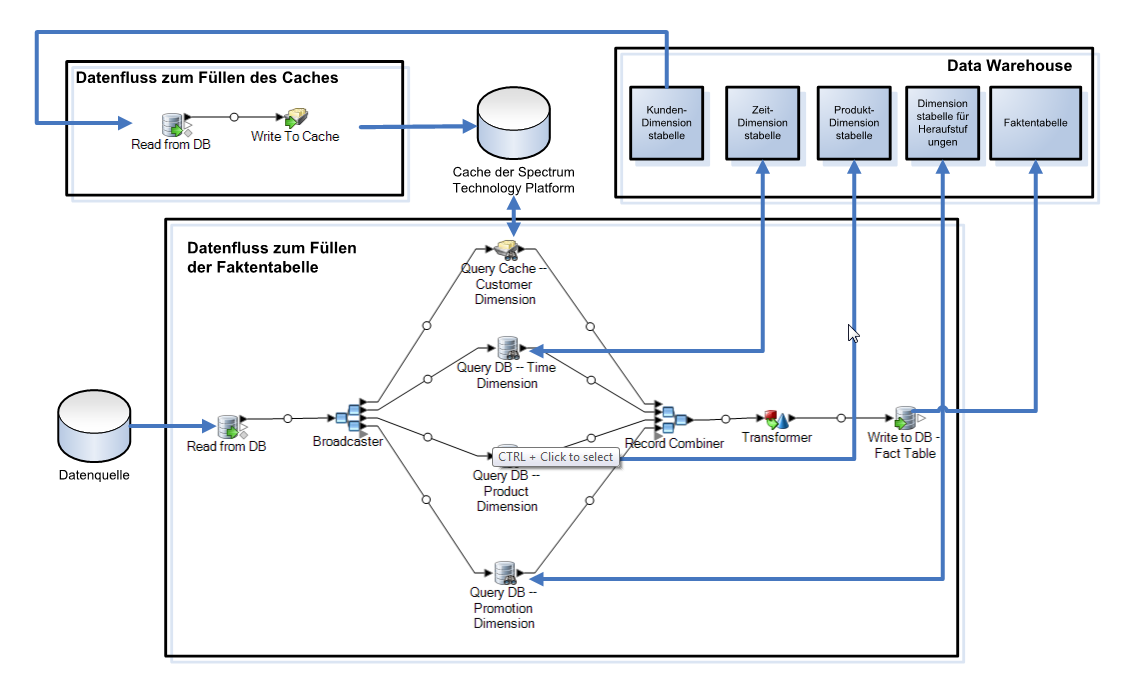
Wenn Sie sicherstellen möchten, dass der Cache jedes Mal, wenn Sie Ihre Faktentabelle aktualisieren, mit den aktuellsten Daten aus der Dimensionstabelle gefüllt wird, können Sie einen Prozessfluss erstellen, der zuerst den Auftrag zum Füllen der Dimensionstabelle und dann den Auftrag zur Aktualisierung der Faktentabelle ausführt. Sie können dann den Prozessfluss ausführen, um beide Datenflüsse nacheinander ablaufen zu lassen. Weitere Informationen zu Prozessflüssen finden Sie im Datenfluss-Designer-Handbuch.