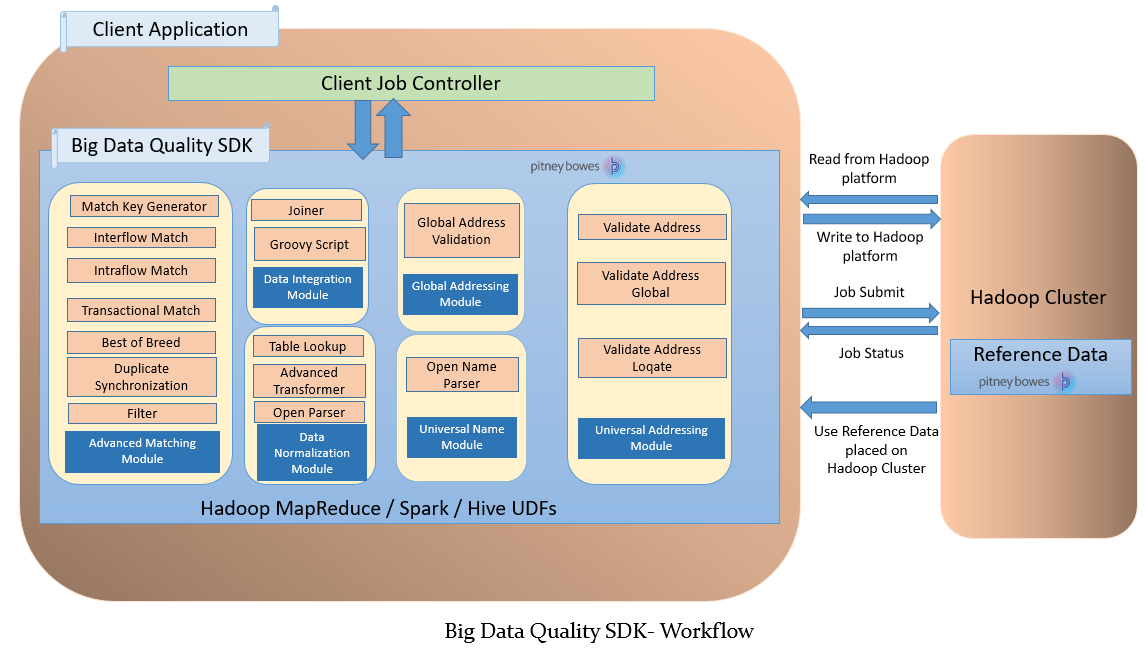
Workflow
To use the SDK, these components are required:
- Spectrum™ Data & Address Quality for Big Data SDK Installation
- The Spectrum™ Data & Address Quality for Big Data SDK JAR file must be installed on your system and available for use by your application.
- Client Application
- The Java application you must create to invoke and run the required Data Quality operations using the SDK. The Spectrum™ Data & Address Quality for Big Data SDK JAR file must be imported into your Java application.
- Hadoop Platform
- On running a job using the Spectrum™ Data & Address Quality for Big Data SDK, data is first read from the
configured Hadoop platform, and after relevant processing, the output data is written to
the Hadoop platform. For this, the access details of the Hadoop platform must be
configured correctly in your machine. For more information, see Installing SDK on Windows and Installing SDK on Linux.Note: You can also use Amazon S3 Native FileSystem (s3n) as input and output for Hadoop MapReduce and Spark jobs.
- Reference Data
- The Reference Data, required by the Spectrum™ Data & Address Quality for Big Data SDK, is placed on the
Hadoop cluster.
- Java API and Hive UDF, UDAF
-
To use the Java API, Hive UDF or Hive UDAF, you can opt to place the reference data on Local Data Nodes or Hadoop Distributed File System (HDFS) :
- Local Data Nodes: The Reference Data is placed on all available data nodes in the cluster.
- Hadoop Distributed File System (HDFS) The Reference Data is placed on an HDFS directory and while running the jobs you can specify if data is to be downloaded as distributed cache or to a local directory. For more information, see Placement and Usage of Reference Data.
Note: The SDK also enables Distributed Caching for enhanced
performance.