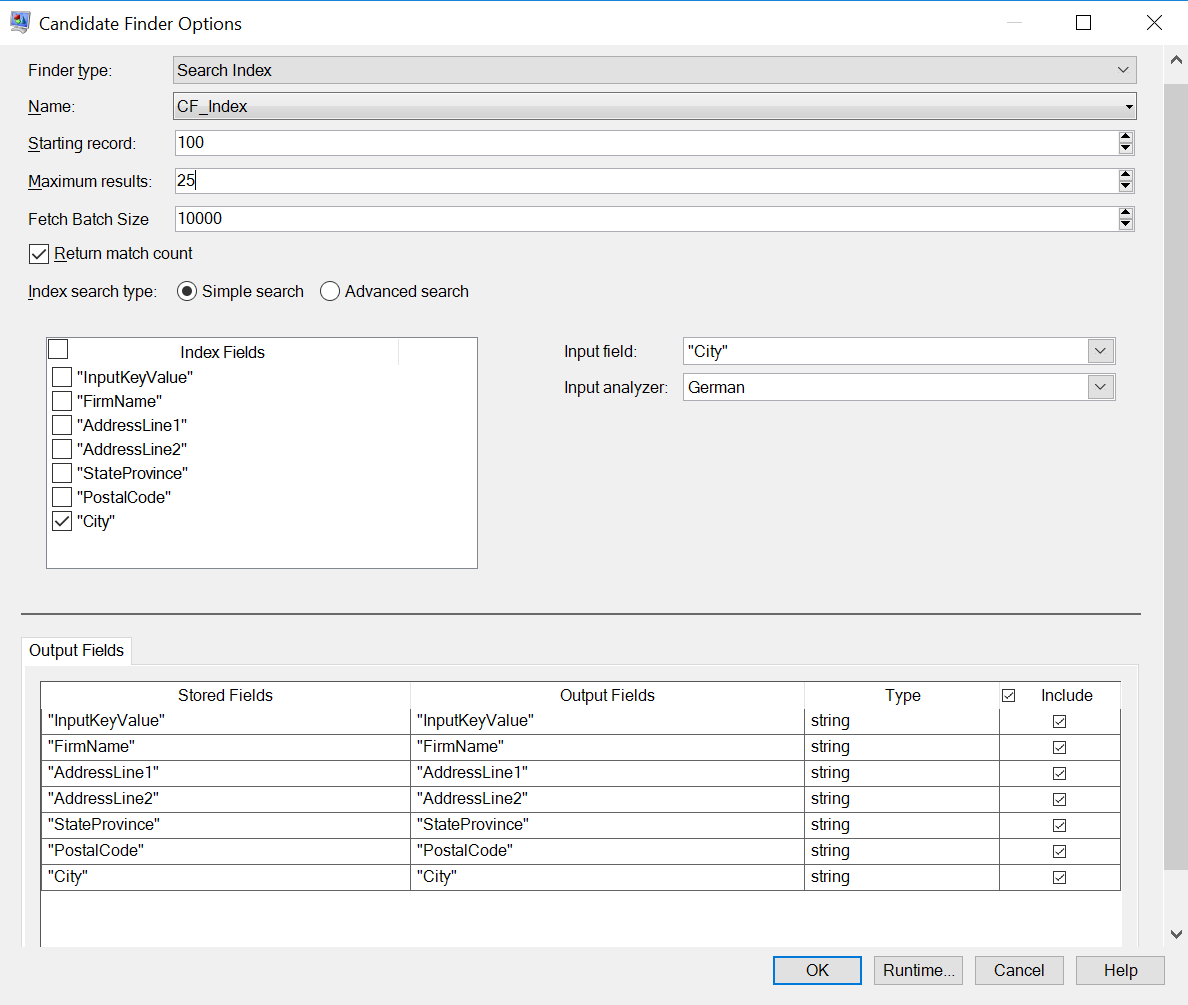
Simple Search Index Options
|
Option Name |
Description / Valid Values |
|---|---|
|
Finder type |
Select Search Index. |
|
Name |
Select the appropriate index that was created using the Write to Search Index stage under the Advanced Matching deployed stages in Enterprise Designer. |
|
Starting record |
Enter the record number on which search results should begin. The default is 1. |
|
Maximum results |
Enter the maximum number of results you want the search index to return. Default is 10.
Note: If the maximum results is arbitrarily large,
process those in batches, using the Fetch Batch
Size field.
|
|
Fetch Batch Size |
If the Maximum results is arbitrarily large, enter the size of batches in which you want the results to be processed. This optimizes processing of large number of records. Default is 10000. The recommended Fetch Batch Size is a value lesser than Maximum results and if the Fetch Batch Size is greater than Maximum results, the records are processed in a single batch. Note: This field is applicable only to cluster supported search engine and
not to the legacy search engine.
|
|
Return match count |
Returns the total number of matches that were made. For example, if you use the default of "10" for the Maximum results field above, only 10 results will be returned. However, if you check this box, the TotalMatchCount output field will tell you how many matches were made during processing. |
| Index search type | Determines the type of index search you want to conduct. Select Simple search. |
|
Index Fields |
Select the index field(s) you want to use for comparison in the simple search. |
|
Input field |
Select the input field you want to use for comparison in the simple search. |
|
Input analyzer |
Specify which analyzer to use to tokenize the input string. One of these:
|
|
Output Fields tab |
Check the Include box to select which
stored fields should be included in the output.
Note: If the
input field is from an earlier stage in the dataflow and it
has the same name as the store field name from the search
index, the values from the input field will overwrite the
values in the output field.
|
- A search index whose Name is "CF_Index"
- A Starting record of 100, which means the search results will begin on the 100th record
- Maximum results set to 25, which means only 25 results should be returned
- Fetch Batch Size to process results in batches
- A selected option to Return match count, which will include all records, not just the 25 we are limiting this view to
- A Simple Index search type
- An Index field of "City" used to match against the "City" input field
- An Input field of "City" used to match against the "City" index field
- A German Input Analyzer to compare fields
- A field map showing that we are returning all fields in the output.