Grammars
A valid parsing grammar contains:
- A root variable that defines the sequence of tokens, or domain pattern, as rule variables.
- Rule variables that define the valid set of characters and the sequence in which those characters can occur in order to be considered a member of a domain pattern. For more information, see Rule Section Commands.
- The input field to parse. Input field designates the field to parse in the source data records.
- The output fields for the resulting parsed data. Output fields define where to store each resulting token that is parsed.
- Characters used to tokenize the input data that you are parsing. Tokenizing characters are characters, like space and hyphen, that determine the start and end of a token. The default tokenization character is a space. Tokenizing characters are the primary way that a sequence of characters is broken down into a set of tokens. You can set the tokenize command to NONE to stop the field from being tokenized. When tokenize is set to None, the grammar rules must include any spaces within its rule definition.
- Casing sensitivity options for tokens in the input data.
- Join character for delimiting matching tokens.
- Matching tokens in tables
- Matching compound tokens in tables
- Defining RegEx tags
- Literal strings in quotes
- Expression Quantifiers (optional). For more information about expression quantifiers, see Rule Section Commands and Expression Quantifiers: Greedy, Reluctant, and Possessive Behavior.
- Other miscellaneous indicators for grouping, commenting, and assignment (optional). For more information about grouped expressions, see Grouping Operator( ).
The rule variables in your parsing grammar form a layered tree structure of the
sequence of characters or tokens in a domain pattern. For example, you can create a
parsing grammar that defines a domain pattern based on name input data that contains the
tokens <FirstName>, <MiddleName>, and
<LastName>.
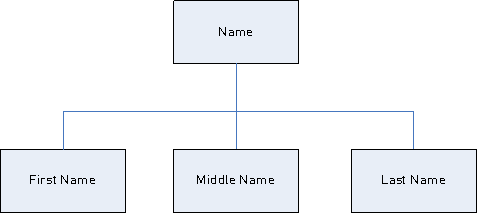
Using the input data:
Joseph Arnold Cowers You can represent that data string as three tokens in a domain pattern:
<root> = <FirstName><MiddleName><LastName>; The rule variables for this domain pattern are:
<FirstName> = <given>;
<MiddleName> = <given>;
<LastName> = @Table("Family Names");
<given> = @RegEx("[A-Za-z]+"); Based
on this simple grammar example, Open Parser tokenizes on spaces and interprets the token
Joseph as a first name because the characters in the first token match
the [A-Za- z]+ definition and the token is in the defined sequence. Optionally, any
expression may be followed by another expression.
Example
<variable> = "some leading string" <variable2>;
<variable2> = @Table ("given") @RegEx("[0-9]+");
A grammar rule is a grammatical statement wherein a variable is equal to one or more expressions. Each grammar rule follows the form:
<rule> =
expression [| expression...];
Grammar rules must follow these rules:
<root>is a special variable name and is the first rule executed in the grammar because it defines the domain pattern.<root>may not be referenced by any other rule in the grammar.- A
<rule>variable may not refer to itself directly or indirectly. When rule A refers to rule B, which refers to rule C, which refers to rule A, a circular reference is created. Circular references are not permitted. - A
<rule>variable is equal to one or more expressions. - Each
expressionis separated by an OR, which is indicated using the pipe character"(|). - Expressions are examined one at a time. The first
expressionto match is selected. No further expressions are examined. - The variable name may be composed of alphabetic, numeric, underscore (_) and hyphen (-). The name of the variable may start with any valid character. If the specified output field name does not conform to this form, use the alias feature to map the variable name to the output field.
An expression may be any of the following types:
- Another variable
- A string consisting of one or more characters in single or double quotes. For
example:
"McDonald" 'McDonald' "O'Hara" 'O\'Hara' 'D"har' "D\"har" - Table
- CompoundTable
- RegEx commands