Parsing U.S. Phone Numbers
This template demonstrates how to parse U.S. phone numbers into component parts. The parsing rule separates each token in the PhoneNumber field and copies each token to four fields: CountryCode, AreaCode, Exchange, and Number.
Business Scenario
You work for a wireless provider and have been assigned a project to analyze incoming phone number data for a growing region of your business.
The following dataflow provides a solution to the business scenario:
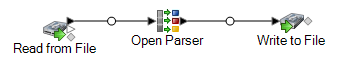
This dataflow template is available in Enterprise Designer. Go to and select ParseUSPhoneNumbers. This dataflow requires the Data Normalization Module.
In this dataflow, data is read from a file and processed through the Open Parser stage. For each data row in the input file, this data flow will do the following:
Read from File
This stage identifies the file name, location, and layout of the file that contains the phone numbers you want to parse.
Open Parser
This stage defines whether to use a culture-specific domain grammar created in the Domain Editor or to define a domain-independent grammar. A culture-specific parsing grammar that you create in the Domain Editor is a validated parsing grammar that is associated with a culture and a domain. A domain-independent parsing grammar that you create in Open Parser is a validated parsing grammar that is not associated with a culture and domain.
In this template, the parsing grammar is defined as a domain-independent grammar.
The Open Parser stage contains a parsing grammar that defines the following commands and expressions:
%Tokenizeis set to None. WhenTokenizeis set toNone, the parsing grammar rule must include any spaces or other token separators within its rule definition.%InputFieldis set to parse input data from the PhoneNumber field.%OutputFieldsis set to separate parsed data into four fields: CountryCode, AreaCode, Exchange, and Number.- The
<root>expression defines pattern of tokens being parsed and includes OR statements (|), such that a valid phone number is: - CountryCode, AreaCode, Exchange, and Number OR
- AreaCode, Exchange, and Number OR
- Exchange and Number
The parsing grammar uses a combination of regular expressions and literal characters to build a pattern for phone numbers. Any characters in double quotes in this parsing grammar are literal characters or a regular expression.
The plus character (+) used in this <root> command is defined as a literal character because it is encapsulated in quotes. You can use single or double quotes to indicate a literal character. If the plus character is used without quotes, it means that the expression it follows can occur one or more times.
The phone number domain rules are defined to match the following character patterns:
- Zero or one occurrence of a "+" character.
- The CountryCode rule, which is a single digit between 0-9.
- Zero or one occurrence of an open parentheses or a hyphen or a space character. Two of these characters occurring in sequence results in a non-match, or in other words, an invalid phone number.
- The AreaCode rule, which is a sequence of exactly three digits between 0-9.
- Zero or one occurrence of an open parentheses or a hyphen or a space character. Two of these characters occurring in sequence results in a non-match, or in other words, an invalid phone number.
- The Exchange rule, which is a sequence of exactly three digits between 0-9.
- Zero or one occurrence of an open parentheses or a hyphen or a space character. Two of these characters occurring in sequence results in a non-match, or in other words, an invalid phone number.
- The Number rule, which is a sequence of exactly four digits between 0-9.
The rule variables that define the domain must use the same names as the output fields defined in the required OutputFields command.
The parsing grammar uses a combination of regular expressions and expression quantifiers to build a pattern for U.S. phone numbers. The parsing grammar uses these special characters:
- The "?" character means that a regular expression can occur zero or one time.
- The (|) character indicates an OR condition.
- The ";" character means end of a rule.
Use the Commands tab to explore the meaning of the other special symbols you can use in parsing grammars by hovering the mouse over the description.
To test the parsing grammar, click the Preview tab. Type the phone numbers shown below in the PhoneNumber field and then click Preview.
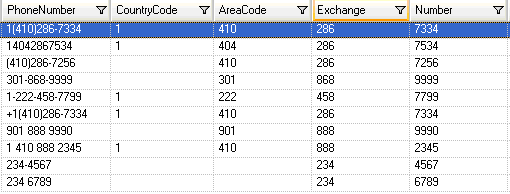
You can also type other valid and invalid phone numbers to see how the input data is parsed.
You can also use the Trace feature to see a graphical representation of either the final parsing results or to step through the parsing events. Click the link in the Trace column to see the Trace Details for the data row.
Write to File
The template contains one Write to File stage. In addition to the input field, the output file contains the CountryCode, AreaCode, Exchange, and Number fields.