Distributed Processing
If you have a very complex job, or you are processing a very large data set such as one containing millions of records, you may be able to improve dataflow performance by distributing the processing of the dataflow to multiple instances of the Spectrum™ Technology Platform server on one or more physical servers.
Once your clustered environment is set up, you can build distributed processing into a dataflow by creating subflows for the parts of the dataflow that you want to distributed to multiple servers. Spectrum™ Technology Platform manages the distribution of processing automatically after you specify just a few configuration options for the subflow.
The following diagram illustrates distributed processing:
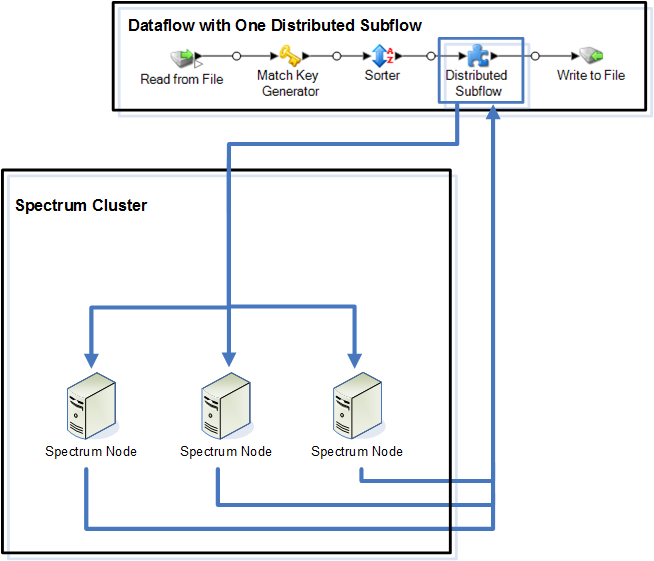
As records are read into the subflow, the data is grouped into batches. These batches are then written to the cluster and automatically distributed to the a node in the cluster which processes the batch. This processing is called a microflow. A subflow may be configured to allow multiple microflows to be processed simultaneously, potentially improving performance of the dataflow. When the distributed instance is finished processing a microflow, it sends the output back into the parent dataflow.
The more Spectrum™ Technology Platform nodes you have the more microflows can be processed simultaneously, allowing you to scale your environment as needed to obtain the performance you require.
Once set up, a clustered environment is easy to maintain since all nodes in the cluster automatically synchronize their configuration, which means the settings you apply through the Management Console and the dataflows you design in Enterprise Designer are available to all instances automatically.