Einführung in das Parsing
Parsing ist der Prozess des Analysierens einer Sequenz von Eingabezeichen in einem Feld und des Aufspaltens des Feldes in mehrere Felder. Beispielsweise verfügen Sie möglicherweise über das Feld „Name“, das den Wert „John A. Smith“ enthält. Durch Parsing können Sie das Feld so aufspalten, dass Sie über das Feld „FirstName“ verfügen, das „John“ enthält, über das Feld „MiddleName“, das „A“ enthält“, und über das Feld „LastName“, das „Smith“ enthält.
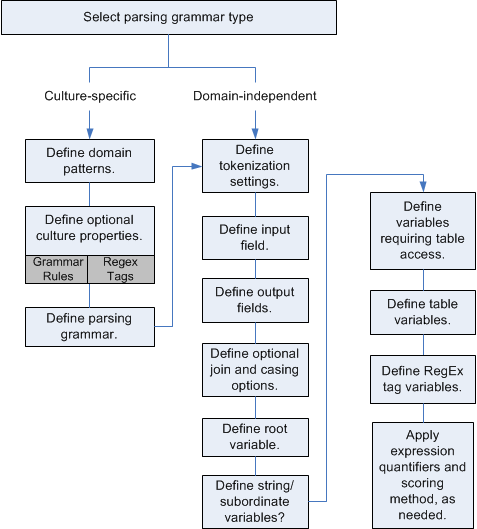
Verwenden Sie zum Erstellen eines Datenflusses, der parst, den „Open Parser“-Schritt. Mit Open Parser können Sie Parsing-Regeln schreiben, die als Grammatiken bezeichnet werden. Eine Grammatik ist eine Reihe von Ausdrücken, die einer Gruppe von benannten Entitäten, die als Domänenmuster bezeichnet werden, eine Sequenz von Zeichen zuordnen. Ein Domänenmuster ist eine Sequenz von einem oder mehreren Token in Ihren Eingabedaten, die Sie als Datenstruktur darstellen möchten, z. B. Name, Adresse oder Kontonummern. Ein Domänenmuster kann aus einer beliebigen Anzahl von Token bestehen, die aus Ihren Eingabedaten geparst werden können. Ein Domänenmuster wird in der Parsing-Grammatik als <Stamm>-Ausdruck dargestellt. Eingabedaten enthalten oft solche Token in schwierig zu verwendenden oder gemischten Formaten. Beispiel:
- Ihre Eingabedaten enthalten Namen in einem einzelnen Feld, das Sie in Vorname und Familienname aufteilen möchten.
- Ihre Eingabedaten enthalten Adressen aus mehreren Kulturen und Sie möchten nur die Adressendaten einer bestimmten Kultur extrahieren.
- Ihre Eingabedaten enthalten frei formatierbaren Text, der eingebettete E-Mail-Adressen enthält, und Sie möchten E-Mail-Adressen extrahieren und mit persönlichen Daten verknüpfen und in einer Datenbank speichern.
Es gibt zwei Arten von Grammatiken: die kulturspezifische und die domänenunabhängige Grammatik. Eine kulturspezifische Parsing-Grammatik ist einer Kultur und/oder Sprache (z. B. Englisch, kanadisches Englisch, Spanisch, mexikanisches Spanisch usw.) und einem bestimmten Datentyp (Telefonnummern, Namen usw.) zugeordnet. Wenn ein „Open Parser“-Schritt für das Durchführen des kulturspezifischen Parsings konfiguriert ist, wird die Parsing-Grammatik der einzelnen Kulturen auf jeden Datensatz angewendet. Die Grammatik mit der besten Parser-Punktzahl (oder die erste mit einer Punktzahl von 100) ist diejenige, deren Ergebnisse zurückgegeben werden. Alternativ können kulturspezifische Parsing-Grammatiken den Wert im Feld „CultureCode“ des Eingabesatzes verwenden und die Daten entsprechend den in der Parsing-Grammatik der Kultur enthaltenen Kultureinstellungen verarbeiten. Kulturspezifische Parsing-Grammatiken können Eigenschaften von einem übergeordneten Element erben. Eine domänenunabhängige Parsing-Grammatik ist weder einer Sprache noch einem bestimmten Datentyp zugeordnet. Domänenunabhängige Parsing-Grammatiken erben keine Eigenschaften von einem übergeordneten Element und ignorieren Informationen aus dem Feld „CultureCode“ in den Eingabedaten.
Open Parser analysiert eine Sequenz von Zeichen in Eingabefeldern und kategorisiert diese durch einen Prozess namens Tokenisierung in eine Sequenz von Token. Tokenisierung ist der Prozess der Begrenzung und Klassifizierung von Abschnitten einer Zeichenfolge mit Eingabezeichen in eine Reihe von Token auf Grundlage von Trennzeichen (auch als Tokenisierungszeichen bezeichnet), wie z. B. Leerzeichen, Bindestrich und andere. Die Token werden dann in von Ihnen angegebenen Ausgabefeldern platziert.
Das folgende Diagramm veranschaulicht den Prozess der Erstellung einer Parsing-Grammatik: