Grammatiken
Eine gültige Parsing-Grammatik enthält:
- Eine Stammvariable, die die Sequenz von Token bzw. Domänenmustern als Regelvariablen definiert.
- Regelvariablen, die den gültigen Satz von Zeichen und die Reihenfolge definieren, in der diese Zeichen auftreten können, um als Mitglied eines Domänenmusters betrachtet zu werden. Weitere Informationen finden Sie unter Befehle des Regelabschnitts.
- Das zu parsende Eingabefeld. Eingabefeld bezeichnet das zu parsende Feld in den Quelldatensätzen.
- Die Ausgabefelder für die resultierenden geparsten Daten. Ausgabefelder definieren, wo die einzelnen resultierenden Token, die geparst werden, gespeichert werden sollen.
- Zeichen, die für die Tokenisierung der von Ihnen geparsten Eingabedaten verwendet werden. Tokenisierungszeichen sind Zeichen, wie z. B. Leerzeichen und Bindestrich, die den Anfang und das Ende eines Tokens bestimmen. Das Standardtokenisierungszeichen ist ein Leerzeichen. Tokenisierungszeichen stellen die primäre Möglichkeit dar, dass eine Sequenz von Zeichen in eine Reihe von Token aufgeschlüsselt wird. Sie können den Befehl „tokenize“ auf NONE festlegen, um eine Tokenisierung des Feldes zu beenden. Wenn der Befehl „tokenize“ auf „None“ festgelegt ist, müssen die Grammatikregeln alle Leerzeichen innerhalb der zugehörigen Regeldefinition enthalten.
- Optionen für die Beachtung von Groß-/Kleinschreibung für Token in den Eingabedaten.
- Join-Zeichen für die Begrenzung übereinstimmender Token.
- Übereinstimmende Token in Tabellen
- Übereinstimmende zusammengesetzte Token in Tabellen
- Definieren von RegEx-Tags
- Literale Zeichenfolgen in Anführungszeichen
- Ausdrucksquantifizierer (optional). Weitere Informationen zu Ausdrucksquantifizierern finden Sie unter Befehle des Regelabschnitts und Ausdrucksquantifizierer: gieriges, widerwilliges und besitzergreifendes Verhalten.
- Verschiedene andere Indikatoren für Gruppierung, Kommentar und Zuweisung (optional). Weitere Informationen zu gruppierten Ausdrücken finden Sie unter Grouping-Operator ().
Die Regelvariablen in Ihrer Parsing-Grammatik bilden eine überlagerte Baumstruktur der Sequenz von Zeichen oder Token in einem Domänenmuster. Sie können z. B. eine Parsing-Grammatik erstellen, die ein Domänenmuster auf Grundlage von Namenseingabedaten definiert, die die Token <<FirstName>, /><<MiddleName>und /><<LastName> enthalten.
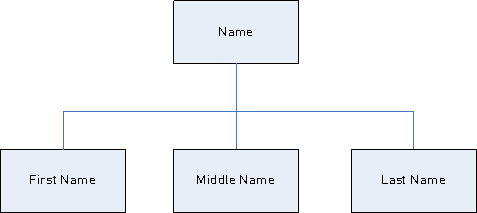
Verwendung der Eingabedaten:
Joseph Arnold Cowers Sie können diese Datenzeichenfolge in Form von drei Token in einem Domänenmuster darstellen:
<root> = <FirstName><MiddleName><LastName>; Die Regelvariablen für dieses Domänenmuster sind:
<FirstName> = <given>;
<MiddleName> = <given>;
<LastName> = @Table("Family Names");
<given> = @RegEx("[A-Za-z]+"); Basierend auf diesem einfachen Grammatikbeispiel versieht Open Parser Leerzeichen mit Token und interpretiert das Token Joseph als Vornamen, da die Zeichen im ersten Token mit der Definition [A-Za- z] + übereinstimmen und sich das Token in der definierten Sequenz befindet. Optional kann jedem Ausdruck ein anderer Ausdruck folgen.
Beispiel
<variable> = "some leading string" <variable2>;
<variable2> = @Table ("given") @RegEx("[0-9]+");
Eine Grammatikregel ist eine grammatische Anweisung, wobei eine Variable gleich einem oder mehreren Ausdrücken ist. Jede Grammatikregel folgt der folgenden Form:
<rule> =
expression [| expression...];
Die Grammatikregeln müssen den folgenden Regeln folgen:
<root>Ist ein spezieller Variablenname und die erste Regel, die in der Grammatik ausgeführt wird, da sie das Domänenmuster definiert.Auf<root>kann nicht durch eine andere Regel in der Grammatik verwiesen werden.- Die Variable
<rule>kann sich nicht direkt oder indirekt auf sich selbst beziehen. Wenn Regel A auf Regel B verweist, die sich auf Regel C bezieht, die auf Regel A verweist, wird ein kreisförmiger Verweis erstellt. Kreisförmige Verweise sind nicht zulässig. - Die Variable
<rule>ist gleich einem oder mehrerer Ausdrücke. - Jeder
expressionwird durch ein OR getrennt, das mit dem Pipe-Zeichen (|) angegeben wird. - Die Ausdrücke werden einzeln überprüft. Der erste übereinstimmende
expressionwird ausgewählt. Es werden keine weiteren Ausdrücke überprüft. - Der Variablenname kann aus alphabetischen Zeichen, numerischen Zeichen, Unterstrich (_) und Bindestrich (-) bestehen. Der Name der Variablen kann mit einem beliebigen gültigen Zeichen beginnen. Wenn der angegebene Ausgabefeldname nicht dieser Form entspricht, verwenden Sie das Alias-Feature, um den Variablennamen dem Ausgabefeld zuzuordnen.
Ein Ausdruck kann einer der folgenden Typen sein:
- Eine andere Variable
- Eine Zeichenfolge, die aus einem oder mehreren Zeichen in einfachen oder doppelten Anführungszeichen besteht. Beispiel:
"McDonald" 'McDonald' "O'Hara" 'O\'Hara' 'D"har' "D\"har" - Tabelle
- CompoundTable
- RegEx-Befehle