Vergleichen von Datensätzen einer Quelle mit Datensätzen einer anderen Quelle
In dieser Prozedur wird beschrieben, wie ein „Interflow Match“-Schritt verwendet wird, um Datensätze in einer Quelle zu identifizieren, die Datensätzen in einer anderen Quelle entsprechen. Die erste Quelle enthält verdächtige Datensätze und die zweite Quelle enthält Kandidatendatensätze. Der Datenfluss vergleicht nur Datensätze einer Quelle mit Datensätzen einer anderen Quelle. Es versucht nicht, Datensätze aus derselben Quelle miteinander zu vergleichen. Der Datenfluss gruppiert Datensätze in Sammlungen mit übereinstimmenden Datensätzen und schreibt diese Sammlungen in eine Ausgabedatei.
-
Ziehen Sie einen „Match Key Generator“-Schritt auf die Arbeitsfläche und verbinden Sie ihn mit einem der Quellschritte.
Wenn Sie beispielsweise einen „Read from File“-Quellschritt verwenden, sieht Ihr Datenfluss jetzt folgendermaßen aus:
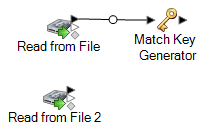
Match Key Generator erstellt einen nicht eindeutigen Schlüssel für jeden Datensatz, der dann von Vergleichsschritten verwendet werden kann, um Gruppen potenzieller Datensatzdubletten zu identifizieren. Vergleichsschlüssel erleichtern den Vergleichsprozess, da sie Ihnen erlauben, Datensätze nach Vergleichsschlüssel zu gruppieren und dann nur Datensätze innerhalb dieser Gruppen zu vergleichen.
Anmerkung: Sie fügen später einen zweiten „Match Key Generator“-Schritt hinzu. Fürs Erste benötigen Sie nur einen Schritt auf der Arbeitsfläche. -
Verbinden Sie die Kopie von „Match Key Generator“ mit dem anderen Quellschritt.
Bei Verwendung eines „Read from File“-Eingabeschrittes etwa würde Ihr Datenfluss jetzt folgendermaßen aussehen:
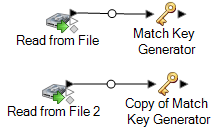
Der Datenfluss enthält nun zwei „Match Key Generator“-Schritte, die für jede Quelle mit exakt den gleichen Regeln Vergleichsschlüssel erzeugen. Die identische Konfiguration der „Match Key Generator“-Schritte ist wesentlich dafür, dass dieser Datenfluss ordnungsgemäß funktioniert.
-
Ziehen Sie einen „Interflow Match“-Schritt auf die Arbeitsfläche und verbinden Sie die einzelnen „Match Key Generator“-Schritte mit ihm.
Bei Verwendung eines „Read from File“-Eingabeschrittes etwa würde Ihr Datenfluss jetzt folgendermaßen aussehen:
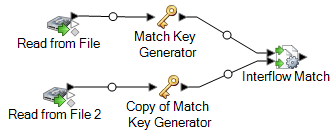
-
Ziehen Sie einen Datenladeschritt auf die Arbeitsfläche und verbinden Sie ihn mit dem „Interflow Match“-Schritt.
Bei Verwendung eines „Write to File“-Datenladeschrittes würde Ihr Datenfluss so aussehen:
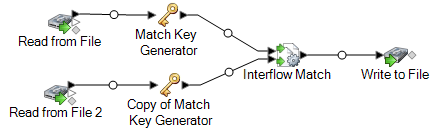
Sie haben jetzt einen Datenfluss, der Datensätze aus zwei Datenquellen miteinander vergleicht.
Beispiel für den Vergleich von Datensätzen aus mehreren Quellen
Als Werbesendungsunternehmen möchten Sie Personen identifizieren, die sich in einer „Do-Not-Mail“-Liste befinden, um keine Werbesendung an sie zu senden. Sie verfügen über eine Liste von Empfängern in einer Datei und eine Liste von Personen, die keine Werbesendung in einer anderen Datei (eine Unterdrückungsdatei) erhalten möchten.
Im folgenden Datenfluss wird eine Lösung für dieses Geschäftsszenario bereitgestellt:
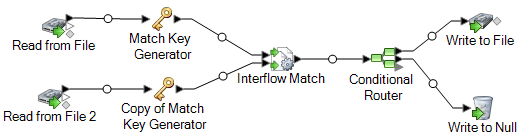
Der „Read from File“-Schritt liest Daten aus Ihrer Mailiste, und der „Read from File 2“-Schritt liest Daten aus der Unterdrückungsliste. Die beiden „Match Key Generator“-Schritte sind identisch konfiguriert, sodass sie einen Vergleichsschlüssel erzeugen, der von „Interflow Match“ verwendet werden kann, um Gruppen potenzieller Übereinstimmungen zu bilden. „Interflow Match“ identifiziert Datensätze in der Mailingliste, die sich ebenfalls in der Unterdrückungsdatei befinden, und markiert diese Datensätze als Dubletten. Conditional Router sendet eindeutige Datensätze – d. h. die Datensätze, die nicht in der Unterdrückungsliste gefunden wurden – an „Write to File“, damit diese in eine Datei geschrieben werden. Der „Conditional Router“-Schritt sendet alle anderen Datensätze an „Write to Null“. Dort werden sie gelöscht.