Diese Schritte beschreiben, wie Sie einen „Intraflow Match“-Schritt verwenden können, um Datensatzgruppen innerhalb einer einzelnen Datenquelle (wie eine Datei oder Datenbanktabelle) identifizieren können, die bezüglich Ihrer angegebenen Vergleichskriterien übereinstimmen. Der Datenfluss gruppiert Datensätze zu Sammlungen und schreibt die Sammlungen in eine Ausgabedatei.
-
Erstellen Sie im Enterprise Designer einen neuen Datenfluss.
-
Ziehen Sie einen Quellschritt auf die Arbeitsfläche.
-
Doppelklicken Sie auf den Quellschritt und konfigurieren Sie ihn. Anweisungen zum Konfigurieren von Quellschritten finden Sie im Datenfluss-Designer-Handbuch.
-
Ziehen Sie einen „Match Key Generator“-Schritt auf die Arbeitsfläche und verbinden Sie ihn mit dem Quellschritt.
Wenn Sie beispielsweise einen „Read from File“-Quellschritt verwenden, sieht Ihr Datenfluss jetzt folgendermaßen aus:
Match Key Generator erstellt einen nicht eindeutigen Schlüssel für jeden Datensatz, der dann von Vergleichsschritten verwendet werden kann, um Gruppen potenzieller Datensatzdubletten zu identifizieren. Vergleichsschlüssel erleichtern den Vergleichsprozess, da sie Ihnen erlauben, Datensätze nach Vergleichsschlüssel zu gruppieren und dann nur Datensätze innerhalb dieser Gruppen zu vergleichen.
-
Doppelklicken Sie auf den „Match Key Generator“-Schritt.
-
Klicken Sie auf Hinzufügen.
-
Definieren Sie die Regel, die zur Generierung eines Vergleichsschlüssels für jeden Datensatz verwendet werden soll.
Tabelle 1. Match Key Generator-Optionen
|
Name der Option
|
Beschreibung/gültige Werte
|
|
Algorithmus
|
Gibt den Algorithmus an, der verwendet werden soll, um den Vergleichsschlüssel zu generieren. Zur Auswahl stehen: - Consonant
- Gibt die angegebenen Felder mit entfernten Konsonanten zurück.
- Double Metaphone
- Gibt einen auf einer phonetischen Darstellung ihrer Zeichen basierenden Code zurück. „Double Metaphone“ ist eine verbesserte Version des Algorithmus „Metaphone“ und versucht, viele der in unterschiedlichen Sprachen vorkommenden Unregelmäßigkeiten zu berücksichtigen.
- Köln
- Indiziert Namen nach Klang, so wie sie auf Deutsch ausgesprochen werden. Ermöglicht die Codierung von Namen mit derselben Aussprache in derselben Darstellung, sodass sie trotz kleiner Unterschiede bei der Schreibwiese verglichen werden können. Das Ergebnis ist immer eine Folge von Zahlen; Sonderzeichen und Leerzeichen werden ignoriert. Diese Option wurde entwickelt, um auf Einschränkungen von Soundex zu reagieren.
- MD5
- Ein Message Digest-Algorithmus, der einen 128-Bit-Hashwert erzeugt. Dieser Algorithmus wird im Allgemeinen verwendet, um die Datenintegrität zu überprüfen.
- Metaphone
- Gibt einen per Metaphone codierten Schlüssel ausgewählter Felder zurück. Metaphone ist ein Algorithmus, um Wörter anhand ihrer englischen Aussprache zu codieren.
- Metaphone (Spanisch)
- Gibt einen per Metaphone codierten Schlüssel ausgewählter Felder für die spanische Sprache zurück. Dieser Metaphone-Algorithmus codiert Wörter anhand ihrer spanischen Aussprache.
- Metaphone 3
- Übertrifft die Algorithmen „Metaphone“ und „Double Metaphone“ mit genaueren Einstellungen für Konsonanten und inneren Vokalen, was Ihnen ermöglicht, Wörter oder Namen auf phonetischer Basis mehr oder weniger eng mit Suchbegriffen abgeglichen zu erzeugen. Metaphone 3 erhöht die Genauigkeit der phonetischen Codierung auf 98 %. Diese Option wurde entwickelt, um auf Einschränkungen von Soundex zu reagieren.
- NYSIIS
- Phonetischer Codealgorithmus, der eine ungefähr übereinstimmende Aussprache mit der exakten Schreibweise vergleicht und Wörter indiziert, deren Aussprache ähnlich ist. Bestandteil des New York State Identification and Intelligence System. Angenommen, Sie suchen die Daten einer Person in einer Personendatenbank. Sie meinen, dass der Name der Person wie „John Smith“ klingt, er wird aber „Jon Smyth“ geschrieben. Würden Sie eine Suche durchführen, in der nach einer genauen Übereinstimmung mit „John Smith“ gesucht wird, würden keine Ergebnisse zurückgegeben. Wenn Sie jedoch die Datenbank mit dem Algorithmus NYSIIS indizieren und eine erneute Suche mit dem Algorithmus NYSIIS durchführen, wird die richtige Übereinstimmung zurückgegeben, weil vom Algorithmus sowohl „John Smith“ als auch „Jon Smyth“ als „JAN SNATH“ indiziert werden.
- Phonix
- Vorverarbeitet Namenszeichenfolgen, indem mehr als 100 Transformationsregeln auf einzelne Zeichen oder auf Zeichenfolgen angewendet werden. 19 dieser Regeln werden nur angewendet, wenn das bzw. die Zeichen am Anfang der Zeichenfolge stehen, während 12 der Regeln nur angewendet werden, wenn sie in der Mitte der Zeichenfolge stehen. 28 der Regeln werden nur angewendet, wenn sie am Ende der Zeichenfolge stehen. Die transformierte Namenszeichenfolge wird als Code codiert, der aus einem Anfangsbuchstaben gefolgt von drei Stellen besteht (Nullen und doppelt vorhandene Zahlen werden entfernt). Diese Option wurde entwickelt, um auf Einschränkungen von Soundex zu reagieren; sie ist komplexer und deshalb langsamer als Soundex.
- Soundex
- Gibt einen Soundex-Code ausgewählter Felder zurück. Soundex erzeugt einen auf der englischen Aussprache eines Wortes basierenden Code mit fester Länge.
- Teilzeichenfolge
- Gibt einen angegebenen Teil des ausgewählten Feldes zurück.
|
|
Feldname
|
Gibt das Feld an, auf das Sie den ausgewählten Algorithmus anwenden möchten, um den Vergleichsschlüssel zu generieren. Wenn Sie beispielsweise ein Feld mit Namen „LastName“ auswählen und den Soundex-Algorithmus wählen, würde der Soundex-Algorithmus auf die Daten im Feld „LastName“ angewendet, um einen Vergleichsschlüssel zu erzeugen.
|
|
Startposition
|
Gibt die Startposition innerhalb des angegebenen Feldes an. Nicht alle Algorithmen erlauben Ihnen, eine Startposition anzugeben.
|
|
Länge
|
Gibt die Länge der Zeichen an, die ab der Startposition eingeschlossen werden sollen. Nicht alle Algorithmen erlauben Ihnen, eine Länge anzugeben.
|
|
Sonderzeichen entfernen
|
Entfernt alle nicht numerischen und nicht alphabetischen Zeichen wie Bindestriche, Leerzeichen und andere Sonderzeichen aus einem Eingabefeld.
|
|
Eingabe sortieren
|
Sortiert alle Zeichen in einem Eingabefeld oder alle Begriffe in einem Eingabefeld in alphabetischer Reihenfolge. - Zeichen
- Sortiert die Zeichenwerte aus einem Eingabefeld vor dem Erstellen einer eindeutigen ID.
- Begriffe
- Sortiert jeden Begriffswert aus einem Eingabefeld vor dem Erstellen einer eindeutigen ID.
|
-
Klicken Sie auf OK, wenn Sie mit dem Definieren der Regel fertig sind.
-
Wenn Sie weitere Vergleichsregeln hinzufügen möchten, klicken Sie auf Hinzufügen und fügen Sie sie hinzu. Klicken Sie andernfalls auf OK, wenn Sie fertig sind.
-
Ziehen Sie einen „Intraflow Match“-Schritt auf die Arbeitsfläche und verbinden Sie ihn mit dem „Match Key Generator“-Schritt.
Wenn Sie beispielsweise einen „Read from File“-Quellschritt verwenden, sieht Ihr Datenfluss jetzt folgendermaßen aus:

-
Doppelklicken Sie auf den „Intraflow Match“-Schritt.
-
Wählen Sie im Feld Vergleichsregel laden eine der vordefinierten Vergleichsregeln aus, die Sie entweder unverändert verwenden oder nach Bedarf ändern können. Wenn Sie eine neue Vergleichsregel erstellen möchten, ohne eine der vordefinierten Vergleichsregeln als Startpunkt zu verwenden, klicken Sie auf Neu. Im Datenfluss darf lediglich eine benutzerdefinierte Regel enthalten sein.
Anmerkung: Das Feature „Datenflussoptionen“ im Enterprise Designer ermöglicht es, die Vergleichsregel für die Konfiguration zur Laufzeit verfügbar zu machen.
-
Wählen Sie im Feld Gruppieren nach den Vergleichsschlüssel aus.
Datensätze mit demselben Vergleichsschlüssel werden dann zusammen gruppiert. Die Vergleichsregel wird auf Datensätze innerhalb einer Gruppe angewendet, um herauszufinden, ob Dubletten vorhanden sind. Der Vergleichsschlüssel für jeden Datensatz wird vom „Generate Match Key“-Schritt generiert, den Sie weiter oben konfiguriert haben.
-
Weitere Informationen zum Ändern der anderen Optionen finden Sie unter Erstellen einer Vergleichsregel.
-
Klicken Sie auf OK, um Ihre „Intraflow Match“-Konfiguration zu speichern und zur Datenfluss-Arbeitsfläche zurückzukehren.
-
Ziehen Sie einen Datenladeschritt auf die Arbeitsfläche und verbinden Sie ihn mit dem „Generate Match Key“-Schritt.
Bei Verwendung eines „Write to File“-Datenladeschrittes würde Ihr Datenfluss so aussehen:

-
Doppelklicken Sie auf den Datenladeschritt und konfigurieren Sie ihn.
Informationen zum Konfigurieren von Datenladeschritten finden Sie im Datenfluss-Designer-Handbuch.
Sie verfügen jetzt über einen Datenfluss, der Datensätze aus einer einzelnen Quelle vergleicht.
Beispiel zum Vergleichen von Datensätzen aus einer einzelnen Quelle
Als Data Steward in einer Kreditkartengesellschaft möchten Sie Ihre Kundendatenbank analysieren und herausfinden, welche Adressen mehrmals vorhanden sind und welche Namen dort verzeichnet sind, damit Sie die Anzahl der doppelten Kreditkartenangebote, die an denselben Haushalt gesendet werden, minimieren können.
In diesem Beispiel wird gezeigt, wie Sie Mitglieder desselben Haushalts identifizieren, indem Sie Informationen innerhalb einer einzelnen Eingabedatei vergleichen und eine Ausgabedatei erstellen, die einen Datensatz pro Haushalt enthält.
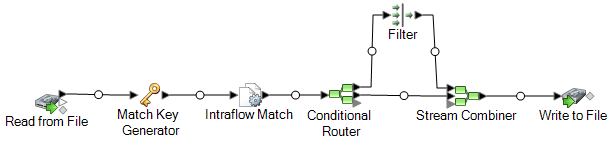
Der „Read from File“-Schritt liest Daten ein, die sowohl eindeutige Datensätze für Haushalte als auch Datensätze enthält, die sich möglicherweise auf denselben Haushalt beziehen. Die Eingabedatei enthält Namen und Adressen.
Der „Match Key Generator“ erstellt einen Vergleichsschlüssel, der bei ähnlichen Datensätzen einen nicht eindeutigen Schlüssel darstellt, um mögliche Dubletten zu identifizieren.
Der „Intraflow Match“-Schritt vergleicht Datensätze, die denselben Vergleichsschlüssel aufweisen, und markiert jeden Datensatz entweder als eindeutigen Datensatz oder als einen von mehreren Datensätzen für denselben Haushalt.
Der „Conditional Router“ sendet Datensätze, die Sammlungen von Datensätzen für jeden Haushalt sind, zum Filter-Schritt, der für jeden Haushalt alle Datensätze bis auf einen herausfiltert und diesen weiter zum „Stream Combiner“-Schritt leitet. Der „Conditional Router“-Schritt sendet außerdem eindeutige Datensätze direkt an den Stream Combiner.
Am Ende erstellt der „Write to File“-Schritt eine Ausgabedatei, die einen Datensatz für jeden Haushalt enthält.