Vergleichen von Datensätzen mithilfe mehrerer Vergleichsregeln
Wenn Sie über zu vergleichende Datensätze verfügen und Sie mehr als einen Vergleichsvorgang verwenden möchten, können Sie einen Datenfluss erstellen, der mehr als einen Vergleichsschlüssel verwendet und dann die Ergebnisse kombiniert, um mehrere separate Kriterien effektiv zu vergleichen. Beispiel: Sie möchten einen Datenfluss erstellen, der Datensätze anhand folgender Kriterien vergleicht:
Name und Adresse stimmen überein.
OR
Geburtsdatum und Ausweisnummer stimmen überein.
Um einen Vergleich anhand dieser Logik durchzuführen, erstellen Sie einen Datenfluss, der in einem Schritt Name und Adresse und in einem anderen Schritt Geburtsdatum und Ausweisnummer vergleicht und dann die entsprechenden Datensätze in einer einzelnen Sammlung kombiniert.
In diesem Thema wird die allgemeine Vorgehensweise beschrieben, wie ein Datenfluss eingerichtet wird, der zwei Vergleichsschritte verwendet. Diese Prozedur verwendet zur Veranschaulichung „Intraflow Match“-Schritte. Sie können diese Technik jedoch auch mit „Interflow Match“-Schritten anwenden.
- Erstellen Sie im Enterprise Designer einen neuen Datenfluss.
- Ziehen Sie einen Quellschritt auf die Arbeitsfläche.
- Doppelklicken Sie auf den Quellschritt und konfigurieren Sie ihn. Anweisungen zum Konfigurieren von Quellschritten finden Sie im Datenfluss-Designer-Handbuch.
-
Definieren Sie den ersten Vergleichsdurchlauf. Die Ergebnisse dieses ersten Vergleichsdurchlaufs bestehen aus Datensätzen, die bezüglich Ihres ersten Satzes an Vergleichskriterien übereinstimmen, in diesem Fall im Namen und in der Adresse.
-
Ziehen Sie einen „Match Key Generator“- und einen „Intraflow Match“-Schritt auf die Arbeitsfläche und verbinden Sie sie gemäß dem folgenden Beispiel:

-
Ziehen Sie einen „Match Key Generator“- und einen „Intraflow Match“-Schritt auf die Arbeitsfläche und verbinden Sie sie gemäß dem folgenden Beispiel:
-
Speichern Sie die Sammlungsnummern aus dem ersten Vergleichsdurchlauf in einem anderen Feld. Dies ist erforderlich, da das Feld „CollectionNumber“ im Verlauf des zweiten Vergleichsdurchlaufs überschrieben wird. Das Feld „CollectionNumber“ muss umbenannt werden, um die Ergebnisse des ersten Vergleichsdurchlaufs zu bewahren.
-
Ziehen Sie einen Transformer-Schritt auf die Arbeitsfläche und verbinden Sie ihn mit dem „Intraflow Match“-Schritt, sodass sich folgender Datenfluss ergibt:

-
Ziehen Sie einen Transformer-Schritt auf die Arbeitsfläche und verbinden Sie ihn mit dem „Intraflow Match“-Schritt, sodass sich folgender Datenfluss ergibt:
-
Definieren Sie den zweiten Vergleichsdurchlauf. Die Ergebnisse dieses zweiten Vergleichsdurchlaufs bestehen aus Datensätzen, die bezüglich Ihres zweiten Satzes an Vergleichskriterien übereinstimmen, in diesem Fall im Geburtsdatum und in der Ausweisnummer.
-
Ziehen Sie einen „Match Key Generator“- und einen „Intraflow Match“-Schritt auf die Arbeitsfläche und verbinden Sie sie gemäß dem folgenden Beispiel:

-
Ziehen Sie einen „Match Key Generator“- und einen „Intraflow Match“-Schritt auf die Arbeitsfläche und verbinden Sie sie gemäß dem folgenden Beispiel:
-
Prüfen Sie, ob im zweiten Vergleichsdurchlauf gefundene Datensatzduplikate auch im ersten Vergleichsdurchlauf gefunden wurden.
-
Führen Sie den Datenfluss nach dem zweiten „Intraflow Match“-Schritt wie unten dargestellt fort:

-
Konfigurieren Sie den „Duplicate Synchronization“-Schritt so, dass Datensätze nach dem Feld „CollectionNumber“ (nach der Sammlungsnummer aus dem zweiten Vergleichsdurchlauf) gruppiert werden. Prüfen Sie dann bei jeder Sammlung, ob Datensätze der Sammlung auch im ersten Vergleichsdurchlauf als Dubletten identifiziert wurden. Wenn welche gefunden wurden, kopieren Sie die Sammlungsnummer aus dem ersten Durchlauf in ein neues Feld namens „CollectionNumberConsolidated“. Konfigurieren Sie dazu Duplicate Synchronization wie folgt:
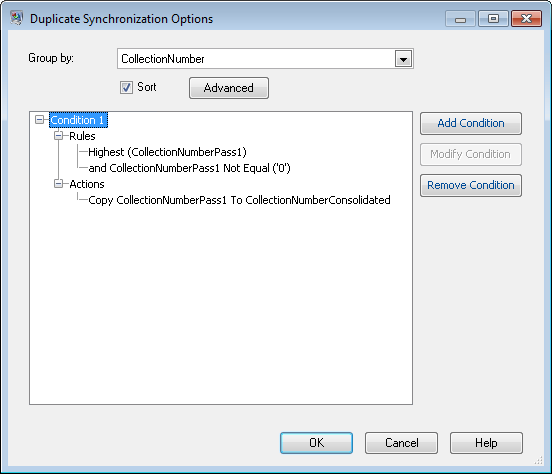
-
Führen Sie den Datenfluss nach dem zweiten „Intraflow Match“-Schritt wie unten dargestellt fort:
- Nach dem Stream Combiner verfügen Sie über Sammlungen von Datensätzen, die in einer der Vergleichsdurchläufe Übereinstimmungen aufwiesen. Das Feld „CollectionNumberConsolidated“ zeigt die übereinstimmenden Datensätze an. Nach dem „Stream Combiner“-Schritt können Sie eine Datenladung oder eine beliebige zusätzliche Verarbeitung anfügen.