Parsen von arabischen Namen
Diese Vorlage zeigt, wie verwestlichte arabische Namen in Komponententeile geparst werden. Die Parsing-Regel separiert jeden Token im Feld Name und kopiert jeden Token in fünf Felder: Kunya, Ism, Laqab, Nasab, Nisba. Diese Aufgabefelder stellen die fünf Teile eines arabischen Namens dar und werden im Geschäftsszenario beschrieben.
Geschäftsszenario
Sie arbeiten für eine Bank, die das arabische Namenssystem besser verstehen möchten, um den Kundendienst mit arabischsprachigen Kunden zu verbessern. Sie hatten Beschwerden von Kunden, deren Rechnungsinformationen nicht den korrekten Namen enthielten. Bei der Bemühung zur Verbesserung der Kundenprivatsphäre möchte die Marketing-Gruppe, für die Sie arbeiten, arabische Kunden durch Marketing-Kampagnen und Telefon-Support besser ansprechen.
Suchen Sie zum besseren Verständnis des arabischen Namenssystems nach Ressourcen im Internet, die das arabische Namenssystem erklären:
Arabische Namen basieren auf einem Namenssystem, das die folgenden Namensteile enthält: Ism, Kunya, Nasab, Laqab und Nisba.
- Ism ist der Hauptname oder Personenname einer arabischen Person.
- Kunya, das sich oftmals auf den erstgeborenen Sohn einer Person bezieht, wird als Ersatz für Ism verwendet.
- Nasab ist ein Patronym oder eine Reihe von Patronymen. Es gibt die Herkunft einer Person durch das Wort „ibn“ oder „bin“ an, was Sohn bedeutet. „Bint“ bedeutet Tochter.
- Laqab dient als Beschreibung der Person. „Al-Rashid“ bedeutet z. B. der Rechtschaffende oder der Rechtgeleiteter. „Al-Jamil“ bedeutet „wunderschön“.
- Nisba beschreibt den Beruf einer Person, die geografische Heimat oder die Abstammung (Stamm, Familie usw.). Es folgt einer Familie durch mehrere Generationen. Nisba ist gemeinsam mit anderen Komponenten des arabischen Namens vielleicht die naheliegendste Entsprechung des westlichen Nachnamens. „Al-Filistin“ bedeutet z. B. Palästinenser.
Im folgenden Datenfluss wird eine Lösung für das Geschäftsszenario bereitgestellt:
Diese Datenflussvorlage ist im Enterprise Designer verfügbar. Öffnen Sie , und wählen Sie ParseArabicNames aus. Dieser Datenfluss erfordert das Data Normalization-Modul.
In diesem Datenfluss werden Daten aus einer Datei gelesen und über den „Open Parser“-Schritt verarbeitet. Für jede Datenzeile in der Eingabedatei führt dieser Datenfluss Folgendes aus:
Read from File
Bei diesem Schritt werden der Dateiname, der Speicherort und das Layout der Datei identifiziert, welche die zu parsenden Namen enthält. Die Datei enthält männliche und weibliche Namen.
Open Parser
Dieser Schritt definiert, ob eine kulturspezifische Domänengrammatik, die im Domäneneditor erstellt wurde, verwendet wird, oder ob eine domänenunabhängige Grammatik definiert wird. Bei einer von Ihnen im Domain Editor erstellten kulturspezifischen Parsing-Grammatik handelt es sich um eine überprüfte Parsing-Grammatik, die einer Kultur und einer Domäne zugeordnet ist. Bei einer von Ihnen in Open Parser erstellten domänenunabhängigen Parsing-Grammatik handelt es sich um eine überprüfte Parsing-Grammatik, die keiner Kultur und keiner Domäne zugeordnet ist.
In dieser Vorlage ist die Parsing-Grammatik als domänenunabhängige Grammatik definiert.
Der „Open Parser“-Schritt enthält eine Parsing-Grammatik, in der folgende Befehle und Ausdrücke definiert sind:
%Tokenizeist auf das Leerzeichen eingestellt (\s). Das bedeutet, dass „Open Parser“ das Leerzeichen zur Separierung des Eingabefeldes in Token verwendet. „Abu Mohammed al-Rahim ibn Salamah“ enthält z. B. fünf Token: Abu, Mohammed, al-Rahim, ibn und Salamah.%InputFieldist so eingestellt, dass Eingabedaten aus dem Feld Name geparst werden.%OutputFieldsist so eingestellt, das geparste Daten in fünf Felder kopiert werden: Kunya, Ism, Laqab, Nasab und Nisba.- Der
<root>-Ausdruck definiert das Muster für arabische Namen: - Kein oder ein Vorkommnis von Kunya
- Genau ein oder zwei Vorkommnisse von Ism
- Kein oder ein Vorkommnis von Laqab
- Kein oder ein Vorkommnis von Nasab
- Keine oder mehrere Vorkommnisse von Nisba
Die Regelvariablen, die die Domäne definieren, müssen die gleichen Namen wie die im erforderlichen Befehl OutputFields definierten Ausgabefelder verwenden.
Die Parsing-Grammatik verwendet eine Kombination aus regulären Ausdrücken und Ausdrucksquantifizierer, um ein Muster für arabische Namen aufzubauen. In der Parsing-Grammatik werden folgende Sonderzeichen verwendet:
- Das Zeichen „?“ bedeutet, dass ein regulärer Ausdruck keinmal oder einmal auftreten kann.
- Das Zeichen „*“ bedeutet, dass ein regulärer Ausdruck null oder mehrere Male auftreten kann.
- Das Zeichen „;“ steht für das Ende einer Regel.
Auf der Registerkarte Befehle können Sie die Bedeutung der anderen in Parsing-Grammatiken verwendbaren Sonderzeichen herausfinden, indem Sie den Mauszeiger über die Beschreibung bewegen.
Standardmäßig sind die Quantifizierer gierig. Gierig bedeutet, dass der Ausdruck so viele Token wie möglich akzeptiert, aber trotzdem einen erfolgreichen Vergleich zulässt. Sie können dieses Verhalten überschreiben, indem Sie ein „?“ für den Vergleich widerwilligen Verhaltens oder ein „+'“ für den Vergleich besitzergreifenden Verhaltens anfügen. Der Vergleich widerwilligen Verhaltens bedeutet, dass der Ausdruck so wenige Token wie möglich akzeptiert, während immer noch ein erfolgreicher Vergleich zulässig ist. Der Vergleich besitzergreifenden Verhaltens bedeutet, dass der Ausdruck so viele Token wie möglich akzeptiert, auch wenn dadurch kein Vergleich möglich ist.
Klicken Sie zum Testen der Parsing-Grammatik auf die Registerkarte Vorschau. Geben Sie die unten aufgeführten Namen in das Feld Name ein, und klicken Sie auf Vorschau.
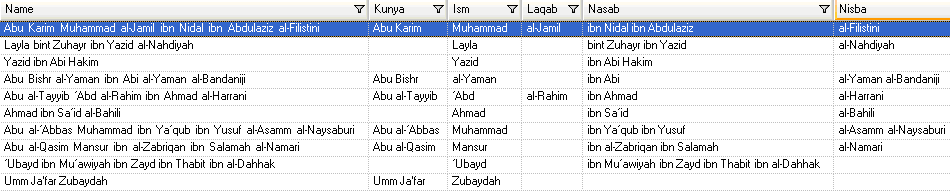
Sie können auch andere gültige und ungültige Namen eingeben, um zu sehen, wie die Eingabedaten geparst werden.
Sie können mithilfe des Features „Ablaufverfolgung“ eine grafische Darstellung eines der endgültigen Parsing-Ergebnisse anzeigen oder die Parsing-Ereignisse durchlaufen. Klicken Sie auf den Link in der Spalte Ablaufverfolgung, um die Ablaufverfolgungsdetails für die Datenzeile anzuzeigen.
Write to File
Die Vorlage enthält einen „Write to File“-Schritt. Zusätzlich zum Eingabefeld enthält die Ausgabedatei die Felder Kunya, Ism, Laqab, Nasab undNisba.