Parsen chinesischer Namen
Diese Vorlage demonstriert, wie chinesische Namen in Komponententeile geparst werden. Die Parsing-Regel trennt die einzelnen Token im Feld Name und kopiert sie in zwei Felder: LastName und FirstName.
Geschäftsszenario
Sie arbeiten für ein Finanzdienstleistungsunternehmen, das untersuchen möchte, ob eine Einschließung der chinesischen Zeichen für seine Chinesisch sprechenden Kunden in diverser Korrespondenz umsetzbar ist.
Sie führen im Internet Recherchen durch, um das chinesische Benennungssystem zu verstehen, und finden folgende Ressource, in der erläutert wird, wie sich chinesische Namen zusammensetzen:
en.wikipedia.org/wiki/Chinese_names
Im folgenden Datenfluss wird eine Lösung für das Geschäftsszenario bereitgestellt:
Diese Datenflussvorlage ist im Enterprise Designer verfügbar. Navigieren Sie zu und wählen Sie ParseChineseNames aus. Dieser Datenfluss erfordert das Data Normalization-Modul.
In diesem Datenfluss werden Daten aus einer Datei gelesen und über den „Open Parser“-Schritt verarbeitet. Dieser Datenfluss geht bei jeder Datenzeile in der Eingabedatei wie folgt vor:
Read from File
Bei diesem Schritt werden der Dateiname, der Speicherort und das Layout der Datei identifiziert, welche die zu parsenden Namen enthält. Die Datei enthält männliche und weibliche Namen.
Open Parser
Dieser Schritt definiert, ob eine kulturspezifische Domänengrammatik, die im Domäneneditor erstellt wurde, verwendet wird, oder ob eine domänenunabhängige Grammatik definiert wird. Bei einer von Ihnen im Domain Editor erstellten kulturspezifischen Parsing-Grammatik handelt es sich um eine überprüfte Parsing-Grammatik, die einer Kultur und einer Domäne zugeordnet ist. Bei einer von Ihnen in Open Parser erstellten domänenunabhängigen Parsing-Grammatik handelt es sich um eine überprüfte Parsing-Grammatik, die keiner Kultur und keiner Domäne zugeordnet ist.
In dieser Vorlage ist die Parsing-Grammatik als domänenunabhängige Grammatik definiert.
Der „Open Parser“-Schritt enthält eine Parsing-Grammatik, in der folgende Befehle und Ausdrücke definiert sind:
%Tokenizeist auf „Keine“ festgelegt. WennTokenizeaufNonegesetzt ist, muss die Parsing-Grammatikregel alle Leerzeichen und andere Token-Trennzeichen innerhalb der Regeldefinition enthalten.%InputFieldist so eingestellt, dass Eingabedaten aus dem Feld Name geparst werden.%OutputFieldsist zum Kopieren geparster Daten in zwei Felder festgelegt: LastName und FirstName.
Der Ausdruck <root> definiert das Muster für chinesische Namen:
- Ein Vorkommen von LastName
- Ein bis drei Vorkommen von FirstName
Die Regelvariablen, die die Domäne definieren, müssen die gleichen Namen wie die im erforderlichen Befehl OutputFields definierten Ausgabefelder verwenden.
Die Regelvariable CJKCharacter definiert das Zeichenmuster für Chinesisch/Japanisch/Koreanisch (CJK). Das Zeichenmuster ist so definiert, dass nur Zeichen in Form von Buchstaben verwendet werden. Die Regel lautet wie folgt:
<CJKCharacter> = @RegEx("([\p{InCJKUnifiedIdeographs}&&\p{L}])"); - Der reguläre Ausdruck
\p{InX}wird verwendet, um einen Unicode-Block für eine bestimmte Kultur anzugeben, in demXfür die Kultur steht. In dieser Instanz lautet die Kultur „CJKUnifiedIdeographs“. - In regulären Ausdrücken ist eine Zeichenklasse ein Satz von Zeichen, die Sie abgleichen möchten. Beispiel: [aeiou] ist die Zeichenklasse, die nur Vokale enthält. Zeichenklassen können innerhalb anderer Zeichenklassen erscheinen und können sich aus dem Vereinigungsoperator (implizit) und dem Schnittmengenoperator (&&) zusammensetzen. Der Vereinigungsoperator bezeichnet eine Klasse mit allen Zeichen, die in mindestens einer der zugehörigen Operandenklassen enthalten sind. Der Schnittmengenoperator bezeichnet eine Klasse mit allen Zeichen, die mit den sich überschneidenden Unicode-Blöcken überlappen.
- Mit dem regulären Ausdruck
\p{L}wird der Unicode-Block angegeben, der nur Buchstaben umfasst.
Klicken Sie zum Testen der Parsing-Grammatik auf die Registerkarte Vorschau. Geben Sie die unten aufgeführten Namen in das Feld Name ein, und klicken Sie auf Vorschau.
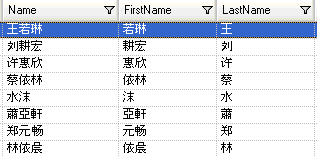
Sie können auch andere gültige und ungültige Namen eingeben, um zu sehen, wie die Eingabedaten geparst werden.
Sie können mithilfe des Features „Ablaufverfolgung“ eine grafische Darstellung eines der endgültigen Parsing-Ergebnisse anzeigen oder die Parsing-Ereignisse durchlaufen. Klicken Sie auf den Link in der Spalte Ablaufverfolgung, um die Ablaufverfolgungsdetails für die Datenzeile anzuzeigen.
Write to File
Die Vorlage enthält einen „Write to File“-Schritt. Neben dem Eingabefeld enthält die Ausgabedatei die Felder LastName und FirstName. Wählen Sie in der Liste der Vergleichsergebnisse ein Vergleichsergebnis aus, und klicken Sie dann auf Entfernen.