Parsen von E-Mail-Adressen
Diese Vorlage demonstriert, wie E-Mail-Adressen in Komponententeile geparst werden. Die Parsing-Regel trennt die einzelnen Token im Feld Email und kopiert sie in drei Felder: Local-Part, DomainName und DomainExtension. Local-Part stellt den Teil des Domänennamens der E-Mail-Adresse dar, DomainName den Domänennamen der E-Mail-Adresse und DomainExtension die Domänenerweiterung der E-Mail-Adresse. Beispiel: Bei pb.com steht „pb“ für den Domänennamen und „com“ für die Domänenerweiterung.
Das Internet ist eine großartige Quelle für öffentlich zugängliche Informationen, die Sie bei Ihren offenen Parsing-Aufgaben unterstützen können. In diesem Beispiel wurden von verschiedenen Internetressourcen Informationen zur E-Mail-Formatierung abgerufen und anschließend zur Erstellung einer Tabelle mit Domänenwerten in „Tabellenverwaltung“ importiert. Die Aufgabe zur Domänenerweiterung, die Sie in dieser Vorlagenaktivität durchführen, demonstriert die Nützlichkeit dieser Methode.
Zudem demonstriert diese Vorlage, wie Tabellendaten, die Sie in „Tabellenverwaltung“ geladen haben, effektiv im Rahmen Ihrer Parsing-Aufgaben für Tabellensuchvorgänge genutzt werden können.
Geschäftsszenario
Sie arbeiten für ein Versicherungsunternehmen, das seine erste E-Mail-Marketingkampagne plant. Ihre Datenbank enthält die E-Mail-Adressen Ihrer Kunden, und Sie wurden darum gebeten, einen Weg zu finden, um sicherzustellen, dass diese E-Mail-Adressen ein gültiges SMTP-Format aufweisen.
Bevor Sie diesen Datenfluss erstellen, müssen Sie eine Tabelle mit gültigen Domänennamenerweiterungen in „Tabellenverwaltung“ laden, damit Sie im Rahmen des Überprüfungsprozesses nach Domänennamenerweiterungen suchen können.
Im folgenden Datenfluss wird eine Lösung für das Geschäftsszenario bereitgestellt:
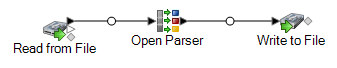
Diese Datenflussvorlage ist im Enterprise Designer verfügbar. Navigieren Sie zu und wählen Sie ParseEmail aus. Dieser Datenfluss erfordert das Data Normalization-Modul.
In diesem Datenfluss werden Daten aus einer Datei gelesen und über den „Open Parser“-Schritt verarbeitet. Für jede Datenzeile in der Eingabedatei führt dieser Datenfluss Folgendes aus:
Erstellen einer Tabelle mit Domänenerweiterungen
Die erste Aufgabe besteht darin, unter „Tabellenverwaltung“ eine „Open Parser“-Tabelle zu erstellen, mit der Sie überprüfen können, ob die Domänenerweiterungen in Ihrer E-Mail-Adresse gültig sind.
- Wählen Sie aus dem Menü Tools den Eintrag Tabellenverwaltung aus.
- Wählen Sie aus der Liste Typ den Eintrag Open Parser aus.
- Klicken Sie auf Neu.
- Geben Sie im Dialogfeld Benutzerdefinierte Tabelle hinzufügen EmailDomains in das Feld Tabellenname ein. Stellen Sie sicher, dass in der Liste Kopieren von der Eintrag Keine ausgewählt ist und klicken Sie anschließend auf OK.
- Klicken Sie, wenn EmailDomains in der Liste Name angezeigt wird, auf Importieren.
- Klicken Sie im Dialogfeld Importieren auf Durchsuchen und suchen Sie die Quelldatei für die Tabelle. Die Standardspeicherort ist:
<drive>:\Program Files\Pitney Bowes\Spectrum\server\modules\coretemplates\data\ Email_Domains.txt. In „Tabellenverwaltung“ wird eine Vorschau der Begriffe angezeigt, die in der Importdatei enthalten sind. - Klicken Sie auf OK. „Tabellenverwaltung“ importiert die Quelldateien und zeigt eine Liste der internen Domänenerweiterungen an.
- Klicken Sie auf Schließen. Die Tabelle EmailDomains wird erstellt. Erstellen Sie jetzt mithilfe der Vorlage „ParseEmail“ den Datenfluss.
Read from File
In diesem Schritt wird der Dateiname, der Speicherort und das Layout der Datei identifiziert, die die zu parsenden Adressen enthält.
Open Parser
In der Parsing-Grammatik des „Open Parser“-Schrittes werden folgende Befehle und Ausdrücke definiert:
%Tokenizeist auf „Keine“ festgelegt. WennTokenizeaufNonegesetzt ist, muss die Parsing-Grammatikregel alle Leerzeichen und andere Token-Trennzeichen innerhalb der Regeldefinition enthalten.%InputFieldist zum Parsen von Eingabedaten aus dem Feld Email_Address festgelegt.%OutputFieldsist zum Kopieren geparster Daten in drei Felder festgelegt: Local-Part, DomainName und DomainExtension.- Der Stammausdruck definiert das Muster der Token, die geparst werden:
<root> = <Local-Part>"@"<DomainName>"."<DomainExtension>;Die Regelvariablen, die die Domäne definieren, müssen die gleichen Namen wie die im erforderlichen Befehl OutputFields definierten Ausgabefelder verwenden.
- In der restlichen Parsing-Grammatik werden die einzelnen Regelvariablen als Ausdrücke definiert.
<Local-Part> = (<alphanum> ".")* <alphanum> | (<alphanum> "_")* <alphanum> ;
<DomainName> = (<alphanum> ".")? <alphanum>;
<DomainExtension> = @Table("EmailDomains")* "."? @Table("EmailDomains");
<alphanum>=@RegEx("[A-Za-z0-9]+");
Die Variable <Local-Part> ist als Textzeichenfolge definiert, die die Variable <alphanum>, den Punkt und eine weitere <alphanum>-Variable enthält.
Bei der Definition der Variable <alphanum> handelt es sich um einen regulären Ausdruck, also um eine beliebige Zeichenfolge mit Zeichen von A bis Z, a bis z und 0 – 9. Die Variable <alphanum> wird in dieser gesamten Parsing-Grammatik verwendet und wird einmal in der letzten Zeile der Parsing-Grammatik definiert.
Zur Erstellung eines Musters für E-Mail-Adressen verwendet die Parsing-Grammatik eine Kombination aus regulären Ausdrücken und Literalzeichen. Bei allen Zeichen, die in dieser Parsing-Grammatik in doppelten Anführungszeichen (") stehen, handelt es sich um Literalzeichen, Namen von Tabellen für Suchvorgänge oder reguläre Ausdrücke. In der Parsing-Grammatik werden folgende Sonderzeichen verwendet:
- Das Zeichen „+“ bedeutet, dass ein regulärer Ausdruck mindestens einmal auftreten kann.
- Das Zeichen „?“ bedeutet, dass ein regulärer Ausdruck keinmal oder einmal auftreten kann.
- Das Zeichen „|“ bedeutet, dass die Variable eine OR-Bedingung aufweist.
- Das Zeichen „;“ steht für das Ende einer Regel.
Auf der Registerkarte Befehle können Sie die Bedeutung der anderen in Parsing-Grammatiken verwendbaren Sonderzeichen herausfinden, indem Sie den Mauszeiger über die Beschreibung bewegen.
Klicken Sie zum Testen der Parsing-Grammatik auf die Registerkarte Vorschau. Geben Sie die unten im Feld E-Mail-Adresse angezeigten E-Mail-Adressen ein und klicken Sie anschließend auf Vorschau.
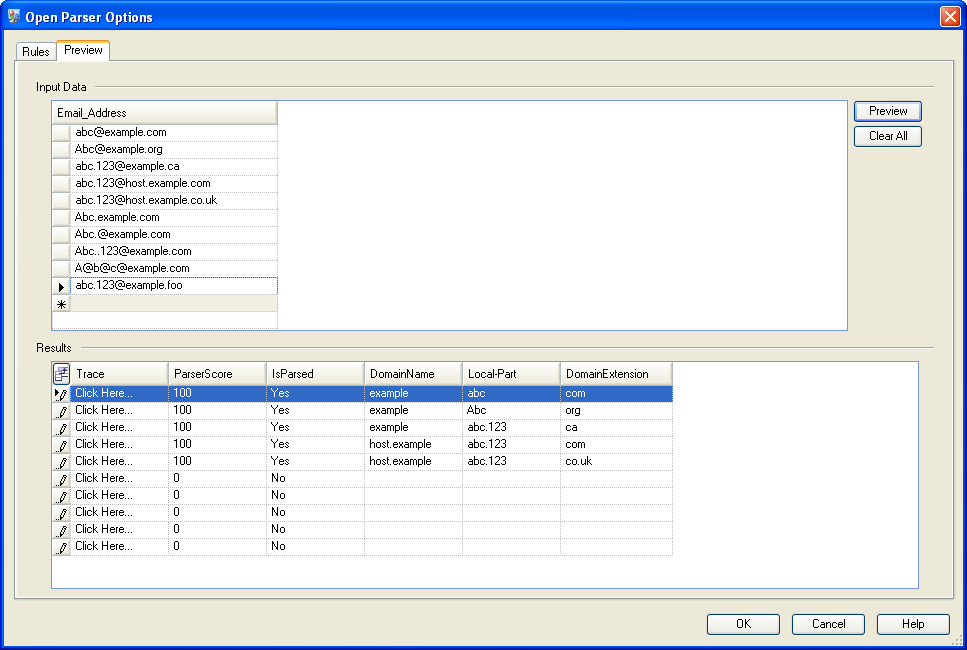
Sie können auch andere E-Mail-Adressen eingeben, um zu sehen, wie die Eingabedaten geparst werden.
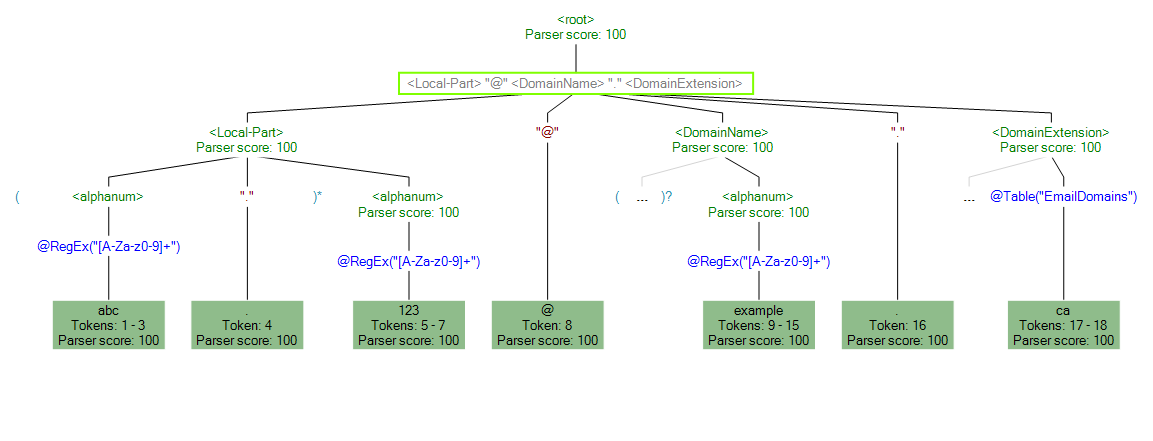
Zudem können Sie mithilfe des Features „Ablaufverfolgung“ eine grafische Darstellung eines der endgültigen Parsing-Ergebnisse anzeigen oder die Parsing-Ereignisse durchlaufen. Klicken Sie auf den Link in der Spalte Ablaufverfolgung, um die Ablaufverfolgungsdetails für die Datenzeile anzuzeigen.
Unter „Ablaufverfolgungsdetails“ wird ein Vergleichsergebnis angezeigt. Vergleichen Sie die Token miteinander, die für die einzelnen Ausdrücke in der Parsing-Grammatik abgeglichen wurden.
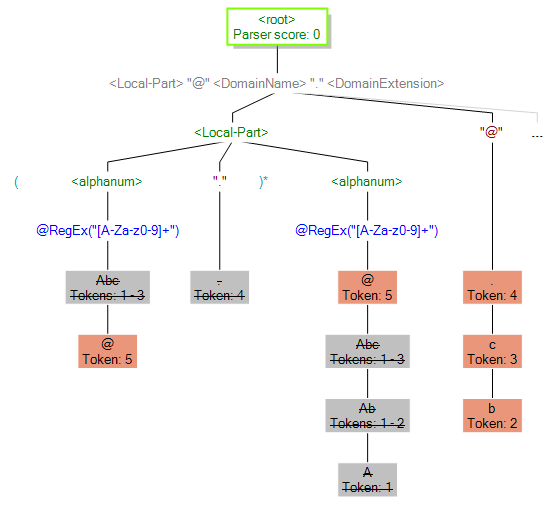
Sie können auch über „Ablaufverfolgung“ nicht übereinstimmende Ergebnisse anzeigen. In der folgenden Grafik wird ein nicht übereinstimmendes Ergebnis dargestellt. Vergleichen Sie die Token miteinander, die für die einzelnen Ausdrücke in der Parsing-Grammatik abgeglichen wurden. Der Grund für die fehlende Übereinstimmung dieser Eingabedaten (Abc.example.com) ist, dass nicht alle abzugleichenden Token darin enthalten waren: Das Zeichen „@“ zum Trennen des Tokens „Local-Part“ von den Token vom Typ „Domain“ ist nicht vorhanden.
Write to File
Die Vorlage enthält einen „Write to File“-Schritt. Neben dem Eingabefeld die Ausgabedatei die Felder Local-Part, DomainName, DomainExtension, IsParsed und ParserScore.