Parsen von spanischen und deutschen Namen
Diese Vorlage demonstriert, wie Namen gemischter Kulturen, z. B. spanische und deutsche Namen, in Komponententeile geparst werden. Die Parsing-Regel trennt die einzelnen Token im Feld Name und kopiert sie in die Felder, die in der Parsing-Grammatik für Personen- und Unternehmensnamen definiert sind. Wählen Sie für weitere Informationen zu dieser Parsing-Grammatik Tools > Open Parser Domain Editor aus. Wählen Sie anschließend die Domäne Personen- und Unternehmensnamen und entweder die Kultur Deutsch (de) oder Spanisch (es) aus.
In dieser Vorlage werden auch über in „Tabellenverwaltung“ enthaltene Tabellendaten Geschlechtscodes auf Personennamen angewendet. Wählen Sie für weitere Informationen zu „Tabellenverwaltung“ Tools > Tabellenverwaltung aus.
Geschäftsszenario
Sie arbeiten für ein Pharmazieunternehmen in Brüssel, das seine Tätigkeiten in Deutschland und Spanien konsolidiert hat. Ihr Unternehmen möchte eine Datenbank für gemischte Kulturen mit Namensdaten implementieren. Sie haben den Auftrag, die Namensvarianten zwischen den zwei Kulturen zu analysieren.
Im folgenden Datenfluss wird eine Lösung für das Geschäftsszenario bereitgestellt:
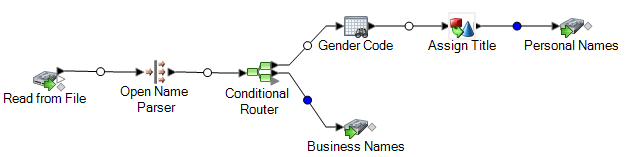
Diese Datenflussvorlage ist im Enterprise Designer verfügbar. Navigieren Sie zu und wählen Sie ParseSpanisch&GermanNames aus. Dieser Datenfluss erfordert das Data Normalization-Modul.
In diesem Datenfluss werden Daten aus einer Datei gelesen und über den „Open Parser“-Schritt verarbeitet. Dieser Datenfluss geht bei jeder Datenzeile in der Eingabedatei wie folgt vor:
Read from File
Bei diesem Schritt werden der Dateiname, der Speicherort und das Layout der Datei identifiziert, welche die zu parsenden Namen enthält. Die Datei enthält männliche und weibliche Namen und umfasst „CultureCode“-Informationen für die einzelnen Namen. Die „CultureCode“-Informationen bezeichnen die Eingabenamen als deutsch (de) oder spanisch (es).
Open Name Parser
„Open Name Parser“ untersucht Namensfelder und vergleicht sie mit den Namensdaten, die in den Namensdatenbankdateien von Spectrum™ Technology Platform gespeichert sind. Basierend auf dem Vergleich parst Open Name Parser die Namensdaten in die Felder „Vorname“, „Zweiter Vorname“ und „Nachname“.
Conditional Router
In diesem Schritt wird die Eingabe weitergeleitet, damit Personennamen an den Schritt „Geschlechtscodes“ und Unternehmensnamen an den Schritt „Unternehmensnamen“ weitergeleitet werden.
Geschlechtscode
Doppelklicken Sie auf diesen Schritt auf der Arbeitsfläche, und klicken Sie anschließend auf Ändern, um Optionen für „Table Lookup“-Regeln anzuzeigen.
Die Option Kategorisieren verwendet den Quellwert als Schlüssel und kopiert den entsprechenden Wert aus dem Tabelleneintrag in das aus der Zielliste ausgewählte Feld. In dieser Vorlage wird Vollständiges Feld ausgewählt, und Quelle wird auf die Verwendung des Feldes FirstName festgelegt. Beim Table Lookup wird das gesamte Feld als eine Zeichenfolge behandelt und der Datensatz gekennzeichnet, wenn die Zeichenfolge als Ganzes kategorisiert werden kann.
Als Ziel wird das Feld GenderCode festgelegt. Zudem werden die in der Tabelle Geschlechtscodes enthaltenen Suchbegriffe für die Kategorisierung männlicher und weiblicher Namen verwendet. Wenn ein Begriff in den Eingabedaten nicht gefunden wurde, weist Table Lookup ihm den Wert U zu. Dieser Wert steht für „Unbekannt“. Wählen Sie für ein besseres Verständnis der Funktionsweise Tools > Tabellenverwaltung aus und wählen Sie dann die Tabelle „Geschlechtscodes“ aus.
Write to File
Die Vorlage enthält zwei „Write to File“-Schritte: einen für Personennamen und einen für Unternehmensnamen. Neben dem Eingabefeld enthält auch die Ausgabedatei für Personennamen die Felder Name, TitleOfRespect,FirstName, MiddleName, LastName, PaternalLastName, MaternalLastName, MaturitySuffix, GenderCode, CultureUsed und ParserScore.
Die Ausgabedatei für Unternehmensnamen enthält die Felder Name, FirmName, FirmSuffix, CulureUsed und ParserScore.