Parsen von US-amerikanischen Telefonnummern
Diese Vorlage demonstriert, wie US-amerikanische Telefonnummern In Komponententeile geparst werden. Die Parsing-Regel trennt die einzelnen Token im Feld PhoneNumber und kopiert sie in vier Felder: CountryCode, AreaCode, Exchange und Number.
Geschäftsszenario
Sie arbeiten für einen Mobilfunkanbieter und wurden einem Projekt zugewiesen, in dem Sie die Daten eingehender Telefonnummern für einen wachsenden Bereich Ihres Unternehmens analysieren sollen.
Im folgenden Datenfluss wird eine Lösung für das Geschäftsszenario bereitgestellt:
Diese Datenflussvorlage ist im Enterprise Designer verfügbar. Navigieren Sie zu und wählen Sie ParseUSPhoneNumbers aus. Dieser Datenfluss erfordert das Data Normalization-Modul.
In diesem Datenfluss werden Daten aus einer Datei gelesen und über den „Open Parser“-Schritt verarbeitet. Dieser Datenfluss geht bei jeder Datenzeile in der Eingabedatei wie folgt vor:
Read from File
In diesem Schritt wird der Dateiname, der Speicherort und das Layout der Datei identifiziert, die die zu parsenden Telefonnummern enthält.
Open Parser
Dieser Schritt definiert, ob eine kulturspezifische Domänengrammatik, die im Domäneneditor erstellt wurde, verwendet wird, oder ob eine domänenunabhängige Grammatik definiert wird. Bei einer von Ihnen im Domain Editor erstellten kulturspezifischen Parsing-Grammatik handelt es sich um eine überprüfte Parsing-Grammatik, die einer Kultur und einer Domäne zugeordnet ist. Bei einer von Ihnen in Open Parser erstellten domänenunabhängigen Parsing-Grammatik handelt es sich um eine überprüfte Parsing-Grammatik, die keiner Kultur und keiner Domäne zugeordnet ist.
In dieser Vorlage ist die Parsing-Grammatik als domänenunabhängige Grammatik definiert.
Der „Open Parser“-Schritt enthält eine Parsing-Grammatik, in der folgende Befehle und Ausdrücke definiert sind:
%Tokenizeist auf „Keine“ festgelegt. WennTokenizeaufNonegesetzt ist, muss die Parsing-Grammatikregel alle Leerzeichen und andere Token-Trennzeichen innerhalb der Regeldefinition enthalten.%InputFieldist zum Parsen von Eingabedaten aus dem Feld PhoneNumber festgelegt.%OutputFieldsist zum Teilen geparster Daten in vier Felder festgelegt: CountryCode, AreaCode, Exchange und Number.- Der Ausdruck
<root>definiert Muster von geparsten Token und umfasst OR-Anweisungen (|), wie z. B., dass sich eine gültige Telefonnummer wie folgt zusammensetzt: - CountryCode, AreaCode, Exchange und Number OR
- AreaCode, Exchange und Number OR
- Exchange und Number
Zur Erstellung eines Musters für Telefonnummern verwendet die Parsing-Grammatik eine Kombination aus regulären Ausdrücken und Literalzeichen. Bei allen Zeichen, die in dieser Parsing-Grammatik in doppelten Anführungszeichen (") stehen, handelt es sich um Literalzeichen oder reguläre Ausdrücke.
Das in diesem <root>-Befehl verwendete Pluszeichen (+) wird als Literalzeichen definiert, da es in Anführungszeichen steht. Für die Angabe eines Literalzeichens können Sie einfache oder doppelte Anführungszeichen verwenden. Wird das Pluszeichen ohne Anführungsstriche verwendet, bedeutet dies, dass der Ausdruck, hinter dem es steht, einmal oder mehrere Male auftreten kann.
Die Domänenregel für Telefonnummern sind so definiert, dass sie folgenden Zeichenmustern entsprechen:
- Null oder einem Vorkommen des Zeichens „+“.
- Der Regel CountryCode, die eine einzelne Ziffer zwischen 0 und 9 darstellt.
- Null oder einem Vorkommen einer geöffneten Klammer, eines Bindestrichs oder eines Leerzeichens ( ). Wenn zwei dieser Zeichen nacheinander auftreten, führt dies zu einer Nichtübereinstimmung, d. h. zu einer ungültigen Telefonnummer.
- Der Regel AreaCode, die eine Sequenz von genau drei Ziffern zwischen 0 und 9 darstellt.
- Null oder einem Vorkommen einer geöffneten Klammer, eines Bindestrichs oder eines Leerzeichens ( ). Wenn zwei dieser Zeichen nacheinander auftreten, führt dies zu einer Nichtübereinstimmung, d. h. zu einer ungültigen Telefonnummer.
- Der Regel Exchange, die eine Sequenz von genau drei Ziffern zwischen 0 und 9 darstellt.
- Null oder einem Vorkommen einer geöffneten Klammer, eines Bindestrichs oder eines Leerzeichens ( ). Wenn zwei dieser Zeichen nacheinander auftreten, führt dies zu einer Nichtübereinstimmung, d. h. zu einer ungültigen Telefonnummer.
- Der Regel Number, die eine Sequenz von genau vier Ziffern zwischen 0 und 9 darstellt.
Die Regelvariablen, die die Domäne definieren, müssen die gleichen Namen wie die im erforderlichen Befehl OutputFields definierten Ausgabefelder verwenden.
Zur Erstellung eines Musters für US-amerikanische Telefonnummern verwendet die Parsing-Grammatik eine Kombination aus regulären Ausdrücken und Ausdrucksquantifizierern. In der Parsing-Grammatik werden folgende Sonderzeichen verwendet:
- Das Zeichen „?“ bedeutet, dass ein regulärer Ausdruck keinmal oder einmal auftreten kann.
- Das Zeichen (|) gibt eine OR-Bedingung an.
- Das Zeichen „;“ steht für das Ende einer Regel.
Auf der Registerkarte Befehle können Sie die Bedeutung der anderen in Parsing-Grammatiken verwendbaren Sonderzeichen herausfinden, indem Sie den Mauszeiger über die Beschreibung bewegen.
Klicken Sie zum Testen der Parsing-Grammatik auf die Registerkarte Vorschau. Geben Sie die unten im Feld PhoneNumber angezeigten Telefonnummern ein und klicken Sie anschließend auf Vorschau.
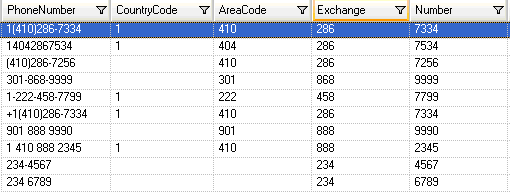
Sie können auch andere gültige und ungültige Telefonnummern eingeben, um zu sehen, wie die Eingabedaten geparst werden.
Zudem können Sie mithilfe des Features „Ablaufverfolgung“ eine grafische Darstellung eines der endgültigen Parsing-Ergebnisse anzeigen oder die Parsing-Ereignisse durchlaufen. Klicken Sie auf den Link in der Spalte Ablaufverfolgung, um die Ablaufverfolgungsdetails für die Datenzeile anzuzeigen.
Write to File
Die Vorlage enthält einen „Write to File“-Schritt. Neben dem Eingabefeld enthält die Ausgabedatei die Felder CountryCode, AreaCode, Exchange und Number.