Konfigurieren erweiterter Optionen
- Lassen Sie Konstante Felder ignorieren aktiviert, damit Felder übersprungen werden, die für die einzelnen Datensätze die gleichen Werte enthalten.
- Lassen Sie p-Werte berechnen aktiviert, um p-Werte für die Parameterschätzungen zu berechnen.
-
Lassen Sie Kollineare Spalte entfernen aktiviert, damit kollineare Spalten während der Modellerstellung automatisch entfernt werden. Dies führt zu einem Koeffizienten von 0 im zurückgegebenen Modell.
Diese Option muss aktiviert werden, wenn p-Werte berechnen ebenfalls aktiviert ist.
-
Lassen Sie Konstanten Begriff einschließen (abfangen) aktiviert, um einen konstanten Begriff im Modell einzuschließen (abzufangen).
Dieses Feld muss aktiviert werden, wenn Kollineare Spalte entfernen ebenfalls aktiviert ist.
-
Wählen Sie einen Solver aus der Dropdown-Liste aus. Beachten Sie, dass „CoordinateDescentNaive“ und „CoordinateDescentNaive“ derzeit experimentell sind.
- Auto
- Solver wird basierend auf Eingabedaten und Parametern bestimmt.
- CoordinateDescentNaive
- IRLSM mit der Version der Kovarianzaktualisierungen der zyklischen Koordinate, die aus der innersten Schleife stammt.
- CoordinateDescentNaive
- IRLSM mit der Version der naiven Aktualisierungen der zyklischen Koordinate, die aus der innersten Schleife stammt.
- IRLSM
- Ideal für Probleme mit einer geringen Anzahl von Prädiktoren oder Lambda-Suchvorgänge mit L1-Penalty.
- L_BFGS
- Ideal für Datasets mit vielen Spalten.
- Lassen Sie Seed für N-fach aktiviert, und geben Sie einen numerischen Ausgangswert ein, um sicherzustellen, dass die Darstellung der Daten bei jeder Datenflussausführung gleich ist, wenn diese in Test- und Trainingsdaten aufgeteilt werden. Deaktivieren Sie dieses Feld, damit die Aufteilung bei jeder Datenflussausführung beliebig erfolgt.
- Aktivieren Sie N-fach und geben Sie die Anzahl der Folds ein, wenn Sie eine Kreuzvalidierung durchführen.
-
Aktivieren Sie Faktorzuweisung, und wählen Sie aus der Dropdown-Liste aus, ob Sie eine Kreuzvalidierung durchführen. Dieses Feld ist nur anwendbar, wenn Sie unter N-fach einen Wert eingegeben haben und Faktorfeld nicht angegeben ist.
- Auto
-
Lässt zu, dass der Algorithmus automatisch eine Option auswählt; derzeit wird „Random“ verwendet.
- Modulo
-
Teilt das Dataset gleichmäßig auf die Folds auf und ist nicht vom Ausgangswert abhängig.
- Random
-
Teilt die Daten zufällig in „N-fach“-Bestandteile ein; diese Einstellung ist für umfangreiche Datasets am besten geeignet.
- Stratified
-
Schichtet die Folds basierend auf der Antwortvariable für Klassifizierungsprobleme. Verteilt Beobachtungen aus den verschiedenen Klassen gleichmäßig auf alle Datasets, wenn ein Dataset in Trainings- und Testdaten aufgeteilt wird. Dies kann nützlich sein, wenn viele Klassen vorhanden sind und das Dataset relativ klein ist.
-
Wenn Sie eine Kreuzvalidierung durchführen, aktivieren Sie Faktorfeld und wählen Sie aus der Dropdown-Liste das Feld aus, das die Faktorindexzuweisung für die Kreuzvalidierung enthält.
Dieses Feld ist nur anwendbar, wenn Sie unter N-fach und Faktorzuweisung keinen Wert eingegeben haben.
- Aktivieren Sie Maximale Iterationen und geben Sie die Anzahl der Trainingsiterationen ein, die erfolgen sollen.
- Aktivieren Sie Ziel-Epsilon und geben Sie den Schwellenwert für die Konvergenz an. Dieser Wert musst zwischen 0 und 1 liegen. Wenn der Zielwert geringer ist als dieser Schwellenwert, wird das Modell konvergiert.
- Aktivieren Sie Beta-Epsilon und geben Sie den Schwellenwert für die Konvergenz an. Dieser Wert musst zwischen 0 und 1 liegen. Wenn der Zielwert geringer ist als dieser Schwellenwert, wird das Modell konvergiert. Wenn die L1-Normalisierung der aktuellen Beta-Änderung unter diesem Schwellenwert liegt, sollten Sie die Verwendung der Konvergenz in Erwägung ziehen.
-
Ein häufiges Problem beim prädiktiven Modeling ist die Überanpassung, wenn ein Analytical Model einem bestimmten Dataset zu sehr (oder genau) entspricht und daher bei der Anwendung auf zusätzliche Daten oder künftige Beobachtungen nicht erfolgreich ist. Eine Methode, um Überanpassungen zu vermeiden, ist die Regularisierung. Wählen Sie den zu verwendenden Regularisierungstyp aus.
- LASSO (Geringster absoluter Schrumpf- und Selektionsoperator)
-
Wählt eine kleine Teilmenge von Variablen mit einem Wert von Lambda aus, der hoch genug ist, um als entscheidend angesehen zu werden. Dies könnte bei korrelierten Prädiktorvariablen nicht gut funktionieren, da eine Variable der korrelierten Gruppe ausgewählt und alle anderen Variablen entfernt werden. Dies wird auch durch hohe Dimensionalität begrenzt; wenn ein Modell mehr Variablen als Datensätze enthält, ist LASSO darauf beschränkt, wie viele Variablen es auswählen kann. „Ridge Regression“ hat diese Einschränkung nicht. Wenn die Anzahl der im Modell enthaltenen Variablen groß ist oder wenn bekannt ist, dass die Lösung spärlich ist, wird LASSO empfohlen.
- Ridge Regression
-
Behält alle Prädiktorvariablen bei und verkleinert ihre Koeffizienten proportional. Wenn korrelierte Prädiktorvariablen vorhanden sind, reduziert „Ridge Regression“ die Koeffizienten der gesamten Gruppe korrelierter Variablen auf Gleichheit. Wenn Sie nicht möchten, dass korrelierte Prädiktorvariablen aus Ihrem Modell entfernt werden, verwenden Sie „Ridge Regression“.
- Elastic Net
-
Kombiniert LASSO und „Ridge-Regression“, indem es als Variablenselektor fungiert und gleichzeitig den Gruppierungseffekt für korrelierte Variablen beibehält (Koeffizienten der korrelierten Variablen werden gleichzeitig verkleinert). „Elastic Net“ ist nicht durch hohe Dimensionalität eingeschränkt und kann alle Variablen auswerten, wenn ein Modell mehr Variablen als Datensätze enthält.
-
Überprüfen Sie den Alpha-Wert, und ändern Sie den Wert, wenn Sie nicht den Standardwert 0,5 verwenden möchten. Der Alpha-Parameter steuert die Verteilung zwischen den Abzügen ℓ1 und ℓ2. Gültige Werte liegen zwischen 0 und 1; ein Wert von 1,0 stellt LASSO dar, und ein Wert von 0,0 erzeugt „Ridge Regression“. Die folgende Tabelle zeigt, wie Alpha und Lambda die Regularisierung beeinflussen.
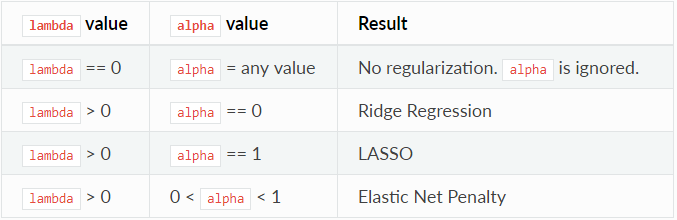 Anmerkung: Das einfache Gleichheitszeichen ist ein Zuweisungsoperator, der „ist“ bedeutet. Das doppelte Gleichheitszeichen ist ein Gleichheitsoperator, der „gleich“ bedeutet.
Anmerkung: Das einfache Gleichheitszeichen ist ein Zuweisungsoperator, der „ist“ bedeutet. Das doppelte Gleichheitszeichen ist ein Gleichheitsoperator, der „gleich“ bedeutet. - Aktivieren Sie den Wert von Lambda, und geben Sie einen Wert an, wenn „Logistic Regression“ nicht die Standardmethode zur Berechnung des Lambda-Wertes verwenden soll, bei der es sich um eine Heuristik handelt, die auf Trainingsdaten basiert. Der Lambda-Parameter steuert den Umfang der angewendeten Regularisierung. Wenn beispielsweise Lambda 0,0 ist, wird keine Regularisierung angewendet und der Alpha-Parameter wird ignoriert.
- Aktivieren Sie Nach optimalem Wert von Lambda suchen, damit „Logistic Regression“ Modelle für den vollständigen Regularisierungspfad berechnet, der beim maximalen Lambda-Wert beginnt (der höchste Lambdawert, der sinnvoll ist; d. h. der niedrigste Wert, der alle Koeffizienten auf Null treibt) und bis zum niedrigsten Lamdba-Wert auf der logarithmischen Skala reicht, wobei die Regularisierungsstärke bei jedem Schritt abnimmt. Das zurückgegebene Modell wird Koeffizienten aufweisen, die dem optimalen Lambda-Wert entsprechen, wie während des Trainings entschieden wurde.
- Aktivieren Sie Frühzeitig stoppen, um die Verarbeitung zu beenden, wenn sich der Trainings- oder Validierungssatz nicht weiter verbessert.
- Aktivieren Sie Maximale zu suchende Lambdas, und geben Sie die maximale Anzahl der Lambdas ein, die während der Lambda-Suche verwendet werden sollen.
- Aktivieren Sie Maximale aktive Prädiktoren, und geben Sie die maximale Anzahl der Prädiktoren ein, die während der Berechnung verwendet werden sollen. Dieser Wert wird als Stoppkriterium verwendet, um einen teuren Modellaufbau mit vielen Prädiktoren zu verhindern.
- Klicken Sie auf OK, um das Modell und die Konfiguration zu speichern, oder fahren Sie mit der nächsten Registerkarte fort.