Transliterator
El componente Transliterator (Transcriptor) convierte una cadena de caracteres entre el alfabeto latino y otros alfabetos. Por ejemplo:
| Origen | Transcripción |
|---|---|
|
|
kyanpasu |
|
Αλφαβητικός Κατάλογος |
|
|
биологическом |
biologichyeskom |
Cabe señalar que la transcripción o transliteración no es una traducción, sino que consiste en la conversión de letras de un alfabeto a otro sin traducir las palabras.
Nota: Con frecuencia, los métodos de transcripción estándar no siguen las reglas de pronunciación de ningún idioma en particular en el sistema de escritura de destino.
La etapa Transliterator admite estas cadenas de caracteres. Como regla general, en esta etapa se siguen las pautas del Grupo de Trabajo sobre Sistemas de Romanización de UNGEGN (UNGEGN Working Group on Romanization Systems). Para obtener más información, consulte www.eki.ee/wgrs.
- Árabe
- El alfabeto utilizado por varios idiomas de Asia y África, lo que incluye el árabe, el persa y el urdu.
- Cirílico
- El alfabeto utilizado por diversos idiomas de Europa del Este y Asia, lo que incluye las lenguas eslavas como el ruso. La etapa Transliterator por lo general sigue la norma ISO 9 para el conjunto de caracteres cirílicos básicos.
- Devanagarí
- El alfabeto que utilizan los idiomas indios, incluidos el hindi y el sánscrito. Este alfabeto proviene del alfabeto brahmi, que es uno de los sistemas de escritura más antiguos utilizados en la India antigua, presente en el sur y el centro de Asia.
- Griego
- El alfabeto utilizado por el idioma griego. Este alfabeto pertenece a la rama helénica de la familia del idioma indoeuropeo.
- Gujaratí
- El alfabeto se utiliza en el estado de Guajarat en India occidental. Es uno de los alfabetos modernos de la India, que se adaptó a partir del alfabeto del devanagari.
- Gurmukhi
- El alfabeto que se utiliza en el idioma indio panyabí. Este alfabeto tiene una influencia considerable del alfabeto del nagari, que es una forma anterior del alfabeto del devanagari.
- Hangul
- El alfabeto utilizado por el idioma coreano. La etapa Transliterator sigue las normas de transcripción del Ministerio de Cultura y Turismo de Corea. Para obtener más información, visite el sitio web The National Institute of the Korean Language.
- Han
- El alfabeto que se utiliza en el idioma chino. Es una rama de la familia del idioma tibetano-birmano, y se ha escrito con cadenas de caracteres que se basan en el tailandés y el chino.
- Chino tradicional/simplificado
-
La etapa Transliterator admite el chino tradicional y el simplificado. Por ejemplo, este es chino tradicional:
 . Este es chino simplificado:
. Este es chino simplificado: 
- Kannada
- El alfabeto que utilizan los idiomas indios del sur, como el konkani. Este alfabeto proviene del alfabeto brahmi de la India antigua.
- Katakana y hiragana
- Uno de los diversos alfabetos que pueden utilizarse para escribir en japonés. La etapa Transliterator utiliza una leve variante del sistema Hepburn. Con el sistema Hepburn, los caracteres ZI (
 ) y DI (
) y DI (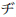 ) se representan como "ji", y los caracteres ZU (
) se representan como "ji", y los caracteres ZU (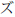 ) y DU (
) y DU (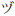 ) se representan como "zu". A los fines de una posible inversión, esto se modificó mínimamente para usar "dji" para DI y "dzu" para DU. La transcripción de Katakana puede invertirse. La transcripción de Hiragana - Katakana no puede invertirse por completo porque hay varias letras en Katakana que no cuentan con un equivalente en Hiragana. Además, la marca de extensión no se usa con Hiragana. La transcripción Hiragana - Latino tampoco puede invertirse porque internamente es una combinación de Katakana - Hiragana e Hiragana - Latino.
) se representan como "zu". A los fines de una posible inversión, esto se modificó mínimamente para usar "dji" para DI y "dzu" para DU. La transcripción de Katakana puede invertirse. La transcripción de Hiragana - Katakana no puede invertirse por completo porque hay varias letras en Katakana que no cuentan con un equivalente en Hiragana. Además, la marca de extensión no se usa con Hiragana. La transcripción Hiragana - Latino tampoco puede invertirse porque internamente es una combinación de Katakana - Hiragana e Hiragana - Latino. - Ancho medio/ Ancho completo
- La etapa Transliterator puede hacer conversiones entre caracteres de medio ancho (con menos espacio) y caracteres de ancho completo (con más espacio). Por ejemplo, este es el medio ancho:
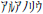 . Este es el ancho completo:
. Este es el ancho completo: 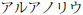 .
. - Latino
- El alfabeto utilizado por la mayoría de los idiomas europeos, como el inglés o el español. Originalmente, lo usaban los romanos de la antigüedad para escribir el latín.
- Malabar
- El alfabeto que utiliza el idioma malabar, el idioma oficial del estado indio de Kerala. En sus inicios, esta cadena de caracteres se escribía con el alfabeto vatteluttu, que significa "escritura redondeada", y que se desarrolló a partir del alfabeto brahmi de la India antigua.
- Oriya
- El alfabeto que utiliza el idioma oriya, el idioma oficial del estado indio de Odisha. El alfabeto oriya se desarrolló a partir del alfabeto kalinga, uno de los numerosos descendientes del alfabeto brahmi de la India antigua.
- Tamil
- El alfabeto que se utiliza en el idioma tamil en varios estados de la India, Sri Lanka y Malasia. En sus inicios, este alfabeto se escribía con una versión del alfabeto brahmi conocida como tamil brahmi.
- Telugu
- El alfabeto que se utiliza en varios idiomas del sur de la India. Este alfabeto proviene del alfabeto brahmi de la India antigua.
- Tailandés
- El alfabeto que utiliza el idioma tailandés. La cadena de caracteres tiene influencias del alfabeto brahmi de la India antigua y de los alfabetos del camboyano.
El componente Transliterator forma parte del módulo Data Normalization (Normalización de datos). Para acceder a una lista de otras etapas, consulte Módulo Data Normalization.