Comparación de registros de un origen a otro origen
Este procedimiento describe cómo usar una etapa de Interflow Match para identificar registros en un origen que coincidan con registros en otro origen. El primer origen contiene registros sospechosos y el segundo contiene registros candidatos. El flujo de datos solo hace coincidir registros de un origen con registros en otro origen. No intenta hacer coincidir registros desde el interior del mismo origen. El flujo de datos agrupa los registros en colecciones de registros coincidentes y escribe dichas colecciones en un archivo de salida.
-
Arrastre hacia el lienzo una etapa Match Key Generator y conéctela a una de las etapas de origen.
Por ejemplo, si está utilizando una etapa de origen Read from File, su flujo de datos tendrá ahora el siguiente aspecto:

Match Key Generator crea una clave no exclusiva para cada registro, que posteriormente se puede usar en las etapas de comparación a fin de identificar grupos de registros potencialmente duplicados. Las claves de cruce facilitan el proceso de comparación al permitir la agrupación de registros por clave de cruce y posteriormente solo comparando los registros al interior de estos grupos.
Nota: Más adelante añadirá una segunda etapa Match Key Generator. Por el momento necesitará en el lienzo solamente una. -
Conecte la copia de Match Key Generator a la otra etapa de origen.
Por ejemplo, si está usando las etapas de entrada Read from File, su flujo de datos tendrá ahora el siguiente aspecto:
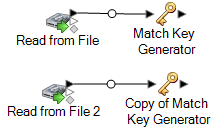
El flujo de datos contiene ahora dos etapas Match Key Generator que producen claves de cruce para cada origen, y que usan exactamente las mismas reglas. Configurar de forma idéntica las etapas Match Key Generator es esencial para el apropiado funcionamiento de este flujo de datos.
-
Arrastre hacia el lienzo una etapa Interflow Match y conecte a esta cada una de las etapas Match Key Generator.
Por ejemplo, si está usando las etapas de entrada Read from File, su flujo de datos tendrá ahora el siguiente aspecto:
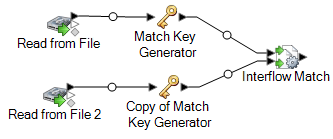
-
Arrastre hacia el lienzo una etapa receptora y conéctela a la etapa Interflow Match.
Por ejemplo, si estuviese utilizando la etapa receptora Write to File, su flujo de datos tendría el siguiente aspecto:

Ahora cuenta con un flujo de datos que se corresponderá con los registros de dos orígenes de datos.
Ejemplo de Cruce de registros de múltiples orígenes
Como empresa de marketing directo, usted desea identificar a las personas que están en una lista de "no enviar correos" de modo que no se les envíen correos. Tiene una lista de destinatarios en un archivo, y en otro archivo tiene una lista de personas que no desean recibir publicidad por correo (es decir, un archivo para eliminaciones).
El siguiente flujo de datos entrega una solución para esta situación empresarial:

La etapa Read from File lee los datos de su lista de correos y la etapa Read from File 2 lee los datos de la lista de eliminaciones. Las dos etapas Match Key Generator están configuradas en forma idéntica, por lo que generan una clave de cruce que puede ser utilizada en Interflow Match para conformar grupos de posibles cruces. Interflow Match identifica registros en la lista de correos que están además en el archivo de eliminaciones y marca dichos registros como duplicados. Conditional Router envía registros únicos, lo que quiere decir que aquellos registros que no se encontraron en la lista de eliminaciones, son enviados a Write to File para que sean escritos en un archivo. La etapa Conditional Router envía todos los demás registros a Write to Null, en donde son descartados.