Este procedimiento describe la forma de utilizar una etapa Intraflow Match para identificar grupos de registros dentro de un origen de datos único (como por ejemplo un archivo o tabla de base de datos) que se relacionan entre sí con base en los criterios de cruce especificados por usted. El flujo de datos agrupa los registros en colecciones y escribe las colecciones en un archivo de salida.
-
Genere un nuevo flujo de datos en Enterprise Designer.
-
Arrastre hacia el lienzo una etapa de origen.
-
Haga doble clic en la etapa de origen y configúrela. Consulte la Guía de Dataflow Designer para obtener instrucciones acerca de cómo configurar etapas de origen.
-
Arrastre hacia el lienzo una etapa Match Key Generator y conéctela a la etapa de origen.
Por ejemplo, si está utilizando una etapa de origen Read from File, su flujo de datos tendrá ahora el siguiente aspecto:
Match Key Generator crea una clave no exclusiva para cada registro, que posteriormente se puede usar en las etapas de comparación a fin de identificar grupos de registros potencialmente duplicados. Las claves de cruce facilitan el proceso de comparación al permitir la agrupación de registros por clave de cruce y posteriormente solo comparando los registros al interior de estos grupos.
-
Haga doble clic en Match Key Generator.
-
Haga clic en Agregar.
-
Defina la regla que se usará para generar una clave de cruce para cada registro.
Tabla 1. Opciones de Match Key Generator
|
Nombre de la opción
|
Descripción / Valores válidos
|
|
Algoritmo
|
Especifica el algoritmo que se utilizará para generar la clave de cruce. Las opciones son: - Consonante
- Devuelve campo especificados con consonantes eliminadas.
- Doble metaphone
- Devuelve un código basado en una representación fonética de sus caracteres. Double Metaphone es una versión mejorada del algoritmo Metaphone e intenta explicar la gran cantidad de irregularidades encontradas en los distintos idiomas.
- Koeln
- Indexa los nombres por sonido, tal como se los pronuncia en alemán. Permite que los nombres que tienen la misma pronunciación se codifiquen con la misma representación, de modo tal que puedan cruzarse a pesar de las pequeñas diferencias en el modo en que se escriben. El resultado es siempre una secuencia de números; los caracteres especiales y los espacios en blanco se ignoran. Esta opción se desarrolló para responder a las limitaciones de Soundex.
- MD5
- Un algoritmo de síntesis del mensaje que produce un valor hash de 128 bits. Este algoritmo suele usarse para comprobar la integridad de los datos.
- Metaphone
- Devuelve una clave codificada Metaphone de campos seleccionados. Metaphone es un algoritmo para codificar palabras utilizando su pronunciación del inglés.
- Metaphone (español)
- Devuelve una clave codificada Metaphone de campos seleccionados para el idioma español. El algoritmo Metaphone codifica palabras con base en su pronunciación en español.
- Metaphone 3
- Mejora los algoritmos de Metaphone y Double Metaphone con parámetros más exactos de consonantes y vocales internas que permiten pronunciar palabras y nombres que, fonéticamente, coinciden en mayor o menor medida con los términos de búsqueda. Metaphone 3 aumenta la precisión de la codificación fonética en un 98%. Esta opción se desarrolló para responder a las limitaciones de Soundex.
- Nysiis
- Algoritmo de codificación fonética que cruza una pronunciación aproximada con una palabra escrita exacta e indexa palabras que se pronuncian de manera similar. Parte del sistema de inteligencia e identificación del estado de Nueva York (New York State Identification and Intelligence System). Supongamos que está buscando información sobre alguien en una base de datos de personas. Cree que el nombre de esa persona suena algo así como "John Smith", pero en realidad se escribe "Jon Smyth". Si busca una coincidencia exacta para "John Smith" no obtendrá resultados. Sin embargo, si indexa la base de datos con el algoritmo de NYSIIS y realiza la búsqueda usando ese mismo algoritmo, obtendrá una coincidencia correcta porque el algoritmo indexa "John Smith" y "Jon Smyth" como "JAN SNATH".
- Phonix
- Preprocesa cadenas de nombres aplicando más de 100 reglas de transformación a caracteres únicos o secuencias de varios caracteres. Diecinueve de esas reglas se aplican solo si los caracteres se encuentran al comienzo de la cadena, mientras que 12 de ellas se aplican solo cuando los caracteres se encuentran en medio de la cadena, y 28 se aplican únicamente si están al final de la cadena. La cadena de nombre transformada se codifica en un código compuesto por la primera letra seguida de tres dígitos (sin ceros ni números duplicados). Esta opción se desarrolló como respuesta a las limitaciones de Soundex; es más compleja y, por lo tanto, más lenta que esta última.
- Soundex
- Devuelve un código Soundex de campos seleccionados. El algoritmo Soundex produce un código de longitud fija basado en la pronunciación en inglés de las palabras.
- Subcadena de caracteres
- Devuelve una porción específica del campo seleccionado.
|
|
Nombre de campo
|
Especifica el campo en el que desea aplicar el algoritmo seleccionado para generar la clave de cruce. Por ejemplo, si selecciona un campo denominado LastName y elije el algoritmo Soundex, se aplicará ese algoritmo a los datos del campo LastName para generar una clave de cruce.
|
|
Posición de inicio
|
Especifica la posición de inicio dentro del campo especificado. No todos los algoritmos permiten especificar una posición inicial.
|
|
Longitud
|
Especifica la longitud, en caracteres, por incluirse desde la posición inicial. No todos los algoritmos permiten especificar una longitud.
|
|
Quitar caracteres irrelevantes
|
Elimina los caracteres que no son numéricos ni alfabéticos, como los guiones, los espacios en blanco y otros caracteres especiales de un campo de entrada.
|
|
Ordenar entrada
|
Ordena alfabéticamente todos los caracteres de un campo de entrada o todos los términos de un campo de entrada. - Caracteres
- Ordena los valores de los caracteres de un campo de entrada antes de crear una ID única:
- Términos
- Ordena el valor de cada término de un campo de entrada antes de crear una ID única.
|
-
Cuando haya terminado de definir la regla, haga clic en Aceptar.
-
Si desea añadir reglas de cruce adicionales, haga clic en Agregar y añádalas, o bien haga clic en Aceptar cuando haya terminado.
-
Arrastre hacia el lienzo una etapa Interflow Match y conéctela a la etapa Match Key Generator.
Por ejemplo, si está utilizando una etapa de origen Read from File, su flujo de datos tendrá ahora el siguiente aspecto:

-
Haga doble clic en Intraflow Match.
-
En el campo Cargar regla de cruce seleccione una de las reglas de cruce predefinidas, que puede usar como está o bien puede modificarla para que se ajuste a sus necesidades. Si desea crear una nueva regla de cruce sin usar una de las reglas de cruce predefinidas como punto de partida, haga clic en Nueva. Solamente puede tener una regla personalizada en un flujo de datos.
Nota: La función Opciones del flujo de datos en Enterprise Designer permite exponer la regla de cruce para la configuración durante la ejecución.
-
En el campo Group by, seleccione MatchKey.
Esto colocará en un grupo los registros que tengan la misma clave de cruce. La regla de cruce se aplica a los registros en un grupo para ver si hay duplicados. La clave de cruce de cada registro será generada por la etapa Generate Match Key que configuró antes en este procedimiento.
-
Para obtener más información acerca de cómo modificar las otras opciones, consulte Generación de reglas de cruce.
-
Haga clic en Aceptar para guardar su configuración de Intraflow Match y vuelva al lienzo del flujo de datos.
-
Arrastre hacia el lienzo la etapa receptora y conéctela a la etapa Generate Match Key.
Por ejemplo, si estuviese utilizando la etapa receptora Write to File, su flujo de datos tendría el siguiente aspecto:

-
Haga doble clic en la etapa receptora y configúrela.
Para obtener información acerca de cómo configurar etapas receptoras, consulte la Guía de Dataflow Designer.
Ahora tiene un flujo de datos que cruzará registros de un origen único.
Ejemplo de Cruce de registros en un origen único de datos
En su calidad de administrador de datos de una empresa de tarjetas de crédito, usted desea analizar su base de datos de clientes y averiguar cuáles direcciones figuran varias veces y con qué nombres, a fin de poder reducir a un mínimo la cantidad de ofertas repetidas de tarjetas de crédito que se envían al mismo hogar.
Este ejemplo demuestra la forma de identificar a los miembros de un mismo hogar por medio de la comparación de información al interior de un único archivo de entrada y la generación de un archivo de salida que contenga solamente un registro por hogar.
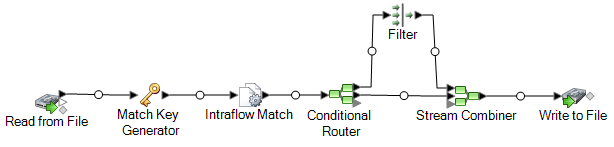
La etapa Read from File lee datos que contienen tanto registros únicos por cada hogar como registros que posiblemente correspondan al mismo hogar. El archivo de entrada contiene nombres y direcciones.
Match Key Generator genera una clave de cruce, la cual se trata de una clave no exclusiva compartida por registros afines que identifica registros como posibles duplicados.
La etapa Intraflow Match compara registros que tienen la misma clave de cruce y marca cada registro ya sea como registro único o como uno de varios registros correspondientes al mismo hogar.
Conditional Router envía registros que son colecciones de registros de cada hogar a la etapa Filter, que filtra cada uno de los archivos correspondientes a cada hogar, salvo uno, el cual envía a a la etapa Stream Combiner. La etapa Conditional Router envía además registros únicos a Stream Combiner en forma directa.
Por último, la etapa Write to File genera un archivo de salida que contiene un registro por cada hogar.