Análisis de nombres españoles y alemanes
Esta plantilla muestra cómo dividir nombres de varias culturas, por ejemplo, nombres españoles y alemanes, en las partes que los componen. La regla de análisis separa cada muestra en el campo Nombre y copia cada muestra en los campos definidos en la gramática de análisis de nombres personales y nombres de empresas. Para obtener más información sobre esta gramática de análisis, seleccione Herramientas > Editor del dominio Open Parser y luego seleccione el dominio de Nombres personales y de empresas y cualquiera de las culturas en Alemán (de) o Español (es).
Esta plantilla también aplica los códigos de género a los nombres personales cuando se utilizan datos de tablas contenidos en Administración de tablas. Para obtener más información sobre Administración de tablas, seleccione Herramientas > Administración de tablas.
Situación empresarial posible
Usted trabaja para una empresa farmacéutica ubicada en Bruselas que ha consolidado sus operaciones en Alemania y España. Su empresa quiere implementar una base de datos de varias culturas que contenga datos de nombre, y es su trabajo analizar las variantes de nombre que existen entre las dos culturas.
El siguiente flujo de datos ofrece una solución ante una posible situación empresarial:
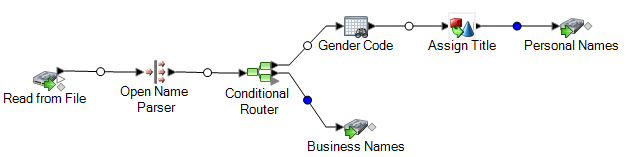
Esta plantilla de flujo de datos está disponible en Enterprise Designer. Vaya a y seleccioneParseSpanish&GermanNames Este flujo de datos requiere el módulo Data Normalization.
En este flujo de datos, los datos se leen desde un archivo y se procesan mediante la etapa Open Parser (Analizador abierto). Para cada fila de datos del archivo de entrada, este flujo de datos hará lo siguiente:
Read from File
La etapa Read from File (Lectura desde archivo) identifica el nombre, la ubicación y el diseño del archivo que contiene los nombres que desea analizar. El archivo contiene tanto nombres masculinos como femeninos e incluye información de CultureCode para cada nombre. La información de CultureCode designa los nombres de entrada como alemanes (de) o españoles (es).
Open Name Parser
Open Name Parser examina los campos de nombre y los compara con los datos almacenados en los archivos de bases de datos de nombres de Spectrum™ Technology Platform. Basado en la comparación, analiza los datos de nombre en los campos Primer nombre, Segundo nombre y Apellido.
Conditional Router
La etapa Conditional Router (Enrutador condicional) envía la entrada para que los nombres personales se dirijan a la etapa Gender Codes (Códigos de género) y los nombres de empresas se dirijan a la etapa Business Names (Nombres de empresas).
Código de género
Haga doble clic en el lienzo de esta etapa y, luego, haga clic en Modificar para mostrar las opciones de regla de búsqueda en tablas.
La opción Categorizar utiliza el valor Fuente como clave y copia el valor correspondiente de la entrada de la tabla en el campo seleccionado en la lista Destino. En esta plantilla, Completar campo se selecciona y Fuente se configura para utilizar el campo FirstName. Table Lookup trata todo el campo como una cadena y marca el registro si es posible categorizar la cadena en su totalidad.
La opción Destino está configurada según el campo Códigos de género y utiliza los términos de búsqueda de la tabla Códigos de género para realizar la categorización de nombres masculinos y femeninos. Si no se encuentra un término en los datos de entrada, Table Lookup le asigna un valor U, en referencia a la palabra "unknown" (desconocido). Para entender mejor cómo funciona esta opción, seleccione Herramientas > Administración de tablas y seleccione la tabla Códigos de género.
Write to File
La plantilla contiene dos etapas Write to File, una para nombres personales y una para nombres de las empresas. Además del campo de entrada, el archivo de salida de nombres personales contiene los campos Name, TitleOfRespect,FirstName, MiddleName, LastName, PaternalLastName, MaternalLastName, MaturitySuffix, GenderCode, CultureUsed, y ParserScore
El archivo de salida de nombres de empresas contiene los campos Name, FirmName, FirmSuffix, CulureUsed, y ParserScore