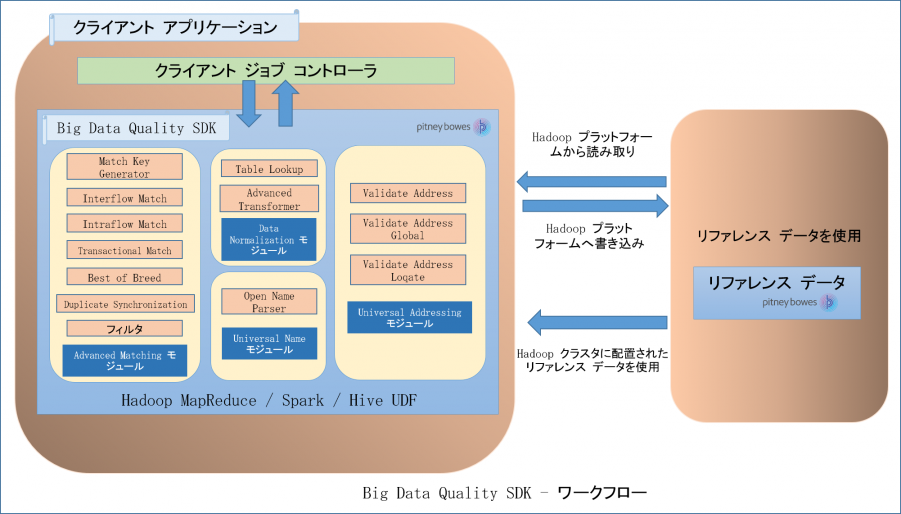
ワークフロー
SDK を使用するには、以下のコンポーネントが必要です。
- Spectrum™ Data & Address Quality for Big Data SDK のインストール
- Spectrum™ Data & Address Quality for Big Data SDK の JAR ファイルをシステムにインストールし、アプリケーションで使用できるようにする必要があります。
- クライアント アプリケーション
- SDK を使用して必要なデータ品質操作を呼び出して実行するために作成する必要がある Java アプリケーション。Spectrum™ Data & Address Quality for Big Data SDK の JAR ファイルを Java アプリケーションにインポートする必要があります。
- Hadoop プラットフォーム
- Spectrum™ Data & Address Quality for Big Data SDK を使用してジョブを実行する際、まず、設定済みの Hadoop プラットフォームからデータが読み込まれ、関連する処理が実行された後、出力データが Hadoop プラットフォームに書き出されます。このため、使用するマシンで Hadoop のアクセスの詳細情報を正しく設定しておく必要があります。詳細については、Windows での SDK のインストールおよびLinux での SDK のインストールを参照してください。注: Amazon S3 ネイティブ ファイル システム (s3n) を Hadoop MapReduce および Spark ジョブの入出力として使用することもできます。
- リファレンス データ
- Spectrum™ Data & Address Quality for Big Data SDK で必要なリファレンス データは、Hadoop クラスタに配置されます。
- Java API および Hive UDF、UDAF
-
Java API、Hive UDF または Hive UDAF を使用する場合は、リファレンス データをローカル データ ノードまたは Hadoop Distributed File System (HDFS) に配置できます。
- ローカル データ ノード: リファレンス データはクラスタ内の使用可能な全てのノードに配置されます。
- Hadoop Distributed File System (HDFS)リファレンス データは HDFS ディレクトリに配置され、ジョブの実行中に、データを分散キャッシュとしてダウンロードするか、ローカル ディレクトリにダウンロードするかを指定できます。詳細については、「リファレンス データの配置および使用方法」を参照してください。
注: また、この SDK では、パフォーマンス向上のための分散キャッシュを実行できます。