パーシングの概要
パーシングは、フィールド内にある連続した入力文字を解析して複数のフィールドに分割する処理です。例えば、Name というフィールドに "John A.Smith" という値が格納されている場合、この値を分割して、FirstName フィールドに "John"、MiddleName フィールドに "A"、LastName フィールドに "Smith" を格納することができます。
パーシングを行うデータフローを作成するには、Open Parser ステージを使用します。Open Parser では、グラマーと呼ばれるパーシング ルールを記述できます。グラマーは、連続した文字列をドメイン パターンと呼ばれる一連の名前付き要素にマップする一連の式です。ドメイン パターンとは、名前、住所、顧客番号のようなデータ構造として表したい入力データの中の、連続した 1 つ以上のトークンです。ドメイン パターンは、入力データからパース可能な任意の数のトークンで構成できます。ドメイン パターンは、<root> 式としてパーシング グラマーに表現されます。入力データには、そのようなトークンが使用しにくいフォーマット、または混在フォーマットで含まれることがしばしばあります。例:
- 入力データには名と姓に分離したい名前が単一のフィールドに含まれている。
- 入力データには複数のカルチャーの住所が含まれており、特定のカルチャーの住所データのみを抽出したい。
- 入力データには電子メール アドレスが埋め込まれた自由形式テキストが含まれており、電子メール アドレスを抽出して個人データとマッチングし、データベースに格納したい。
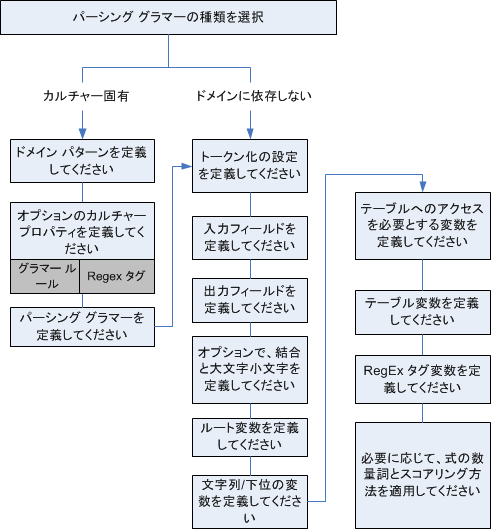
グラマーには、カルチャー固有のものとドメインに依存しないものの 2 種類があります。カルチャー固有のパーシング グラマーは、カルチャーや言語 (英語、カナダ英語、スペイン語、メキシコ スペイン語など)、および特定のタイプのデータ (電話番号、個人名など) に関連付けられています。Open Parser ステージがカルチャー固有のパーシングを実行するように設定されている場合、各カルチャーのパーシング グラマーが各レコードに適用されます。最高のパーサー スコアを取得したグラマー (または最初にスコアが 100 になったグラマー) の結果が返されます。また、カルチャー固有のパーシング グラマーでは入力レコードの CultureCode フィールド内の値を使用し、カルチャーのパーシング グラマーに含まれているカルチャー設定に従ってデータを処理できます。カルチャー固有のパーシング グラマーは、親からプロパティを継承できます。ドメインに依存しないパーシング グラマーは、言語にも特定のタイプのデータにも関連付けられていません。ドメインに依存しないパーシング グラマーは、親からプロパティを継承せず、入力データの CultureCode 情報を無視します。
Open Parser は、入力フィールド内の連続した文字列を解析し、トークン化という処理によって連続したトークンに分類します。トークン化するとは、入力文字列のセクションをスペースやハイフン、その他の区切り文字列 (トークン化文字とも呼ばれます) でそれぞれのトークンに区切り、分類することです。その後、トークンは指定した出力フィールド内に配置されます。
次の図に、パーシング グラマーを作成する処理を示します。