この手順では、Intraflow Match ステージを使用して、単一のデータ ソース (ファイルやデータベース テーブルなど) から、ユーザが指定したマッチング条件に基づいて相互に関連のあるレコードのグループを識別する方法を説明します。このデータフローは、レコードをコレクションにグループ化し、そのコレクションを出力ファイルに書き込みます。
-
Enterprise Designer で、新しいデータフローを作成します。
-
ソース ステージをキャンバスにドラッグします。
-
ソース ステージをダブルクリックして設定します。ソース ステージの設定手順については、『データフロー デザイナー ガイド』を参照してください。
-
Match Key Generator ステージをキャンバスにドラッグし、ソース ステージに接続します。
例えば、Read from File ソース ステージを使用している場合は、データフローは次のようになります。
Match Key Generator は、レコードごとに非ユニーク キーを作成します。この非ユニーク キーは、潜在的な重複レコードのグループを特定するためにマッチング ステージで使用できます。マッチ キーを使用すると、レコードをマッチ キー別にグループ化し、各グループ内でのみレコードを比較できるので、マッチング プロセスが促進されます。
-
Match Key Generator をダブルクリックします。
-
[追加] をクリックします。
-
各レコードのマッチ キーを生成するために使用するルールを定義します。
表 1. Match Key Generator のオプション
|
オプション名
|
説明と有効値
|
|
アルゴリズム
|
マッチ キーの生成に使用するアルゴリズムを次の中から 1 つ指定します。 - Consonant (子音)
- 指定したフィールドから子音を削除して返します。
- Double Metaphone
- 文字の発音表記に基づくコードを返します。Double Metaphone は Metaphone アルゴリズムの改良版で、さまざまな言語に多数存在する不規則性を考慮しています。
- Koeln
- ドイツ語で発音される名前に、音声によってインデックスを付けます。同じ発音を持つ名前を同じ表現にエンコードできるので、綴りに小さな相違があっても、マッチさせることができます。結果は常に一連の数字です。特殊文字および空白は無視されます。このオプションは、Soundex の制限に対応するために作成されました。
- MD5
- 128 ビットのハッシュ値を生成するメッセージ ダイジェスト アルゴリズム。このアルゴリズムは、データの一貫性の確認によく使用されます。
- Metaphone
- 選択したフィールドを Metaphone コード化したキーを返します。Metaphone は、英語の発音を使用して単語をコード化するアルゴリズムです。
- Metaphone (スペイン語)
- 選択したフィールドをスペイン語用に Metaphone コード化したキーを返します。この Metaphone アルゴリズムは、スペイン語の発音を使用して単語をコード化します。
- Metaphone 3
- Metaphone アルゴリズムおよび Double Metaphone アルゴリズムを、より正確な子音および内部母音の設定で改良したもので、単語または名前の一致性を高く、または低くして、音声ベースで語を検索できるようにします。Metaphone 3 では、音声エンコーディングの精度が 98% に向上しています。このオプションは、Soundex の制限に対応するために作成されました。
- Nysiis
- 近似の発音と正確な綴りをマッチさせ、同じように発音される単語にインデックスを付ける、音声コード アルゴリズム。New York State Identification and Intelligence System の一部です。例えば、住民のデータベースで誰かの情報を探しているとします。その人物の名前は "John Smith" のように聞こえますが、実際の綴りは "Jon Smyth" です。"John Smith" の完全一致を探す検索を実行した場合、返される結果はありません。しかし、NYSIIS アルゴリズムを使用してデータベースにインデックスを作成し、再度 NYSIIS アルゴリズムを使用して検索した場合は、正しいマッチが返されます。なぜなら、"John Smith" と "Jon Smyth" は、このアルゴリズムによってどちらも "JAN SNATH" というインデックスが付けられているからです。
- Phonix
- 100 を越える変換ルールを適用することによって、名前文字列を単一の文字またはいくつかの文字のシーケンスに前処理します。これらのルールのうち 19 個は文字がその文字列の先頭にある場合にのみ適用され、12 個はその文字列の中間にある場合にのみ適用され、28 個は文字列の終わりにある場合にのみ適用されます。変換された名前文字列は、開始文字とそれに続く 3 桁 (ゼロおよび重複する数字を削除) で構成されるコードにエンコードされます。このオプションは、Soundex の制限に対応するために作成されました。このオプションは複雑なため、Soundex より遅くなります。
- Sonnex
- このアルゴリズムは、文字の発音表記に基づいて、2 つのフランス語の文字列間の類似性を判断します。
- 選択したフィールドを Sonnex コード化したキーを返します。
- Soundex
- 選択したフィールドの Soundex コードを返します。Soundex は、単語の英語の発音に基づいて、固定長のコードを生成します。
- 部分文字列
- 選択したフィールドの指定した部分を返します。
|
|
フィールド名
|
選択したアルゴリズムを適用してマッチ キーを生成するフィールドを指定します。例えば、LastName というフィールドを選択し、Soundex アルゴリズムを選択した場合、Soundex アルゴリズムが LastName フィールドのデータに適用されて、マッチ キーが生成されます。
|
|
開始位置
|
指定したフィールド内での開始位置を指定します。すべてのアルゴリズムで開始位置を指定できるとは限りません。
|
|
長さ
|
開始位置から含める文字の数を指定します。すべてのアルゴリズムで長さを指定できるとは限りません。
|
|
ノイズ文字の削除
|
ハイフン、空白、その他の特殊文字等、英数字以外の文字を入力フィールドからすべて削除します。
|
|
ソート入力
|
入力フィールド内の文字または語をすべてアルファベット順にソートします。 - 文字
- ユニーク ID を作成する前に、入力フィールドの文字値をソートします。
- 語
- ユニーク ID を作成する前に、入力フィールドの各語値をソートします。
|
-
ルールの定義が終了したら、[OK] をクリックします。
-
さらにマッチ ルールを追加する場合は、[追加] をクリックして追加します。追加するものがなくなったら、[OK] をクリックします。
-
Intraflow Match ステージをキャンバスにドラッグし、Match Key Generator ステージに接続します。
例えば、Read from File ソース ステージを使用している場合は、データフローは次のようになります。

-
Intraflow Match をダブルクリックします。
-
[ロードするマッチ ルール] フィールドで、定義済みのいずれかのマッチ ルールを選択します。このマッチ ルールはそのまま使用することも、必要に応じて変更することもできます。定義済みのいずれかのマッチ ルールを出発点として使用せずに、新しいマッチ ルールを作成する場合は、[新規作成] をクリックします。カスタム ルールは、データフローで 1 つだけ使用できます。
注: Enterprise Designer の [データフロー オプション] 機能を使用すると、マッチ ルールを実行時に公開して設定できます。
-
[グループ化] フィールドで、[マッチ キー] を選択します。
同じマッチ キーを持つレコードがグループに配置されます。マッチ ルールがグループ内のレコードに適用されて、重複があるかどうかが確認されます。各レコードのマッチ キーは、この手順で先に設定した Generate Match Key ステージによって生成されます。
-
他のオプションの変更の詳細については、マッチ ルールの作成を参照してください。
-
[OK] をクリックして Intraflow Match の設定を保存し、データフロー キャンバスに戻ります。
-
シンク ステージをキャンバスにドラッグし、マッチ キーを生成ステージに接続します。
例えば、Write to File シンク ステージを使用した場合、データフローは次のようになります。

-
シンク ステージをダブルクリックして設定します。
シンク ステージの設定方法については、『データフロー デザイナー ガイド』を参照してください。
1 つのソースのレコードをマッチングするデータフローが完成しました。
単一データ ソースのレコードのマッチングの例
クレジット カード会社のデータ管理責任者が、顧客データベースを分析し、複数のレコードに重複して現れる住所とその住所に住む顧客の氏名を洗い出して、同じ世帯に重複して送付されるクレジット カード契約勧誘のダイレクト メールの数を最小限にすることを検討しています。
この例では、単一の入力ファイルの情報を比較して世帯ごとに 1 つのレコードを含む出力ファイルを作成することによって、同じ世帯のメンバーを識別する方法を示します。
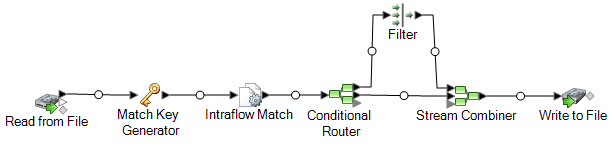
Read from File ステージは、世帯ごとのユニーク レコードと、同じ世帯のものである可能性があるレコードの両方を含むデータを読み込みます。入力ファイルには名前と住所が含まれます。
Match Key Generator は、重複の可能性があるレコードを意味する類似レコードに共通して与えられる非ユニーク キーであるマッチ キーを作成します。
Intraflow Match ステージは、同じマッチ キーを持つレコードを比較し、ユニークなレコードまたは同じ世帯の複数のレコードの 1 つとして各レコードをマークします。
Conditional Router は各世帯のレコードのコレクションであるレコードを Filter ステージに送信し、Filter ステージは世帯ごとに 1 レコードだけを残して他のすべてのレコードを除外し、Stream Combiner ステージに送ります。Conditional Router ステージはユニーク レコードも Stream Combiner に直接送ります。
最後に、Write to File ステージは世帯ごとに 1 レコードを含む出力ファイルを作成します。