フラット ファイルの例
フラット ファイルを入力に使用する Write to Hub データフローは、次のようになります。
Read from File の設定
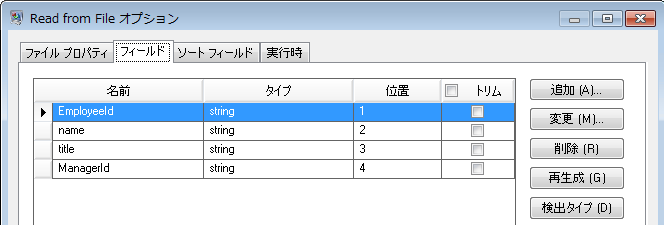
- 従業員 ID (EmployeeID)
- 名前
- タイトル
- 管理者 ID (ManagerID)

管理者 ID を持たない従業員が 2 人いることに注意してください。この 2 人 (Tom Smith と Mary Hansen) はともにディレクターであるため、この例においては管理者がいません。その他の従業員にはすべて、ManagerID フィールドにその従業員の管理者を示す番号が含まれています。例えば、Paula Sheen のレコードの ManagerID フィールドには "1" が含まれており、Tom Smith が彼女の管理者であることを示しています。
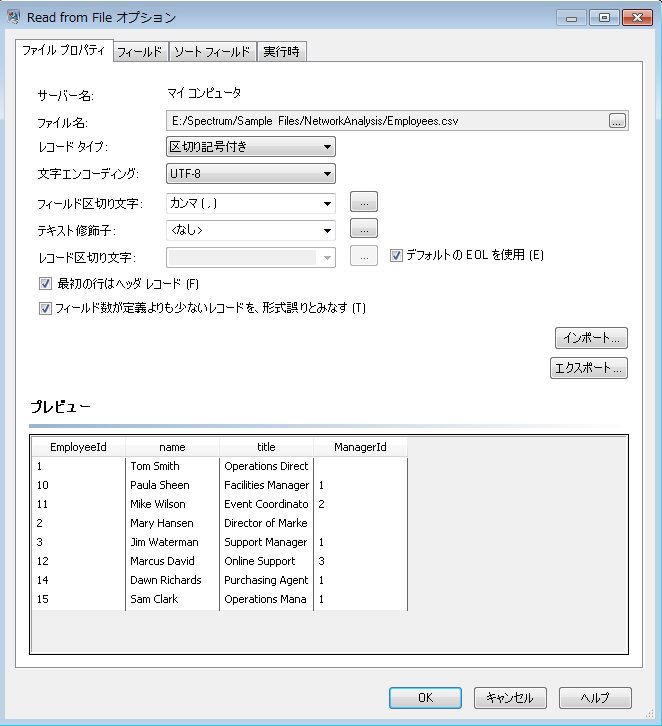
この入力ファイルを使用するように設定した場合、Read from File ステージは次のようになります。
Write to Hub の設定
次に Write to Hub ステージを設定します。モデルに "Employees" という名前を付け、モデルを構成するエンティティと関連性を含むようにステージを設定します。
ここでは組織図に似たモデルを作成しているため、エンティティは、数値 ID を割り当てられた従業員になります。[エンティティを追加] ダイアログ ボックスにおいてまず、参照ボタンをクリックして [フィールド スキーマ] ダイアログ ボックスにアクセスし、使用可能なフィールドの一覧から "EmployeeId" を選択します。これが、この例のモデルにおける最初のエンティティ グループです。
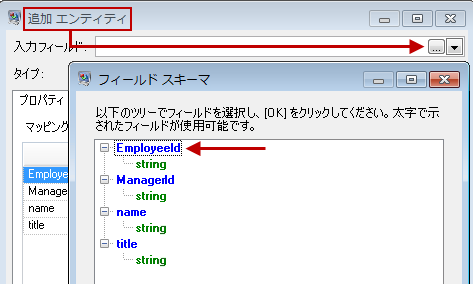
次に、[タイプ] フィールドに "Employee" を設定し、"name" と "title" のチェック ボックスをオンにします。これらのフィールドからの情報を、モデル内の EmployeeID エンティティのプロパティとして使用するためです。
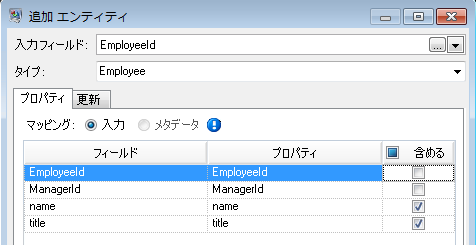
Employee エンティティのプロパティを設定したら、次に処理オプションを設定します。[更新] タブでは、モデル内のプロパティが一旦設定された後に、それらを更新するかどうか、既存データを上書きするかどうかを指定できます。例えばこの例では、Mary Hansen が 2 回出現します。レコード 4 では従業員として参照され、レコード 3 では管理者として参照されるためです。Write to Hub は 2 回目に Mary Hansen を処理する際に、最初の処理の結果として設定されたデータを上書きするか、または削除するという選択肢があります。[プロパティを空の入力データで上書きしない] (これがデフォルトです) を選択すると、更新が生じた場合に新しいプロパティが作成されて既存のプロパティが上書きされますが、最初の処理で設定されたプロパティが 2 回目の処理では欠落していた場合に、プロパティを空白にすることはしません。このオプションでは、レコードの読み込み順序がモデルに影響を与えないことも保証されます。
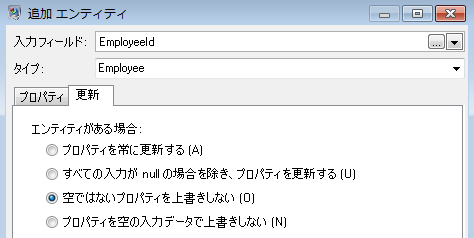
[プロパティを常に更新する] を選択すると、データは常に上書きされ、最後のプロパティ データ セットのみがモデルに反映されることになります。[すべての入力が null の場合を除き、プロパティを更新する] を選択すると、新しいレコードのすべてのフィールドが空白である場合を除き、データは常に上書きされます。最後に、[空でないプロパティを上書きしない] を選択した場合は、フィールドが空白でない限り、任意のフィールドの最初のデータ セットが維持されます。このオプションでは、空白でない最初のデータ セットが保持されることになります。
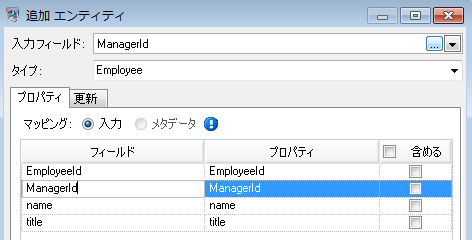
上記の手順を繰り返して "ManagerId" をモデルの 2 つめのエンティティ グループとして追加します。ManagerID と EmployeeID は入力ファイルにおいて異なるフィールドですが、どちらのエンティティもタイプが “Employee” に設定されています。ManagerID を異なるタイプに設定すると、モデルには中間レベルの管理者に対する 2 つのエンティティが含まれることになります。例えば、Jim Waterman は従業員としてのエンティティと管理者としてのエンティティを持つことになります。どちらのエンティティのタイプも "Employee" に設定することにより、Jim Waterman などの管理者は、モデルにおいて 1 つのエンティティのみを持ちます。このエンティティには、(従業員から) 入ってくる複数のエンティティと、(対応する管理者へと) 出ていく 1 つのエンティティがあります。ManagerID エンティティにはプロパティを追加していないことに注意してください。これらのフィールド (name、title) の値は従業員に適用されるものであり、管理者に適用されるものではないからです。また、[更新] タブでは [プロパティを空の入力データで上書きしない] というデフォルト設定をそのまま使用します。
この例の最終的な [エンティティ] タブは、次のようになります。
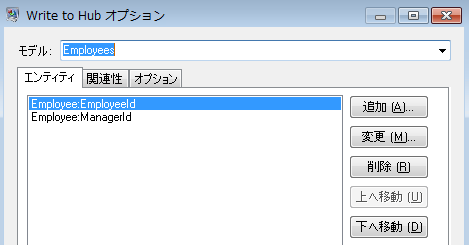
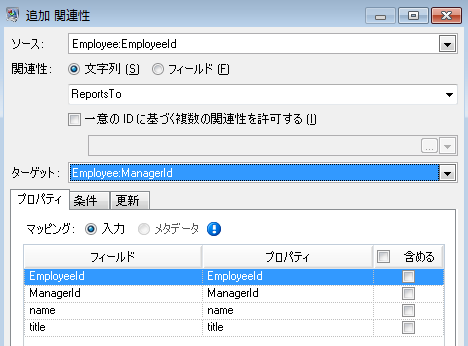
次に、[関連性] タブを設定します。[関連性を追加] ダイアログ ボックスにおいてまず、[エンティティ] タブ上で作成されたエンティティの一覧から関連性のソースを選択します。この例のエンティティ間の関連性は、報告階層構造 (従業員から管理者) を反映するものなので、"Employee:EmployeeID" エンティティをソースとして選択します。次に、"String" を関連性の名前として選択し、"reports_to" (報告する) というテキストを入力します。続いて、[エンティティ] タブ上で作成されたエンティティの一覧から関連性のターゲットを選択します。この例では、"Employee:ManagerID" を選択します。"報告する" 関係の代わりに "管理する" 関係を使用する場合は、ソース フィールドとターゲット フィールドの選択は逆になります。
この例の最終的な [関連性] タブは、次のようになります。
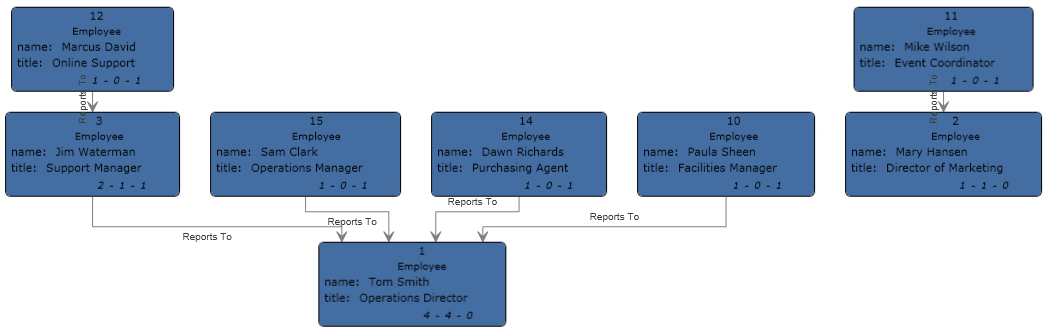
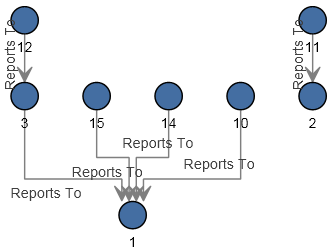
これでデータフローの設定は完了し、完成モデルは Relationship Analysis Client において次のように表されます。この例では、エンティティに対してデフォルト設定を適用する階層レイアウトが使用されています。
これと同じデータを、以下のようにパネル スタイルで表示することもできます。パネル スタイルを使用することの利点は、各エンティティに関連付けられたプロパティが参照できることです。