Introduction to Parsing
Parsing is the process of analyzing a sequence of input characters in a field and breaking it up into multiple fields. For example, you might have a field called Name which contains the value "John A. Smith" and through parsing, you can break it up so that you have a FirstName field containing "John", a MiddleName field containing "A" and a LastName field containing "Smith."
To create a dataflow that parses, use the Open Parser stage. Open Parser allows you to write parsing rules called grammars. A grammar is a set of expressions that map a sequence of characters to a set of named entities called domain patterns. A domain pattern is a sequence of one or more tokens in your input data that you want to represent as a data structure, such as name, address, or account numbers. A domain pattern can consist of any number of tokens that can be parsed from your input data. A domain pattern is represented in the parsing grammar as the <root> expression. Input data often contains such tokens in hard-to-use or mixed formats. For example:
- Your input data contains names in a single field that you want to separate into given name and family name.
- Your input data contains addresses from several cultures and you want to extract address data for a specific culture only.
- Your input data includes free-form text that contains embedded email addresses and you want to extract email addresses and match them up with personal data and store them in a database.
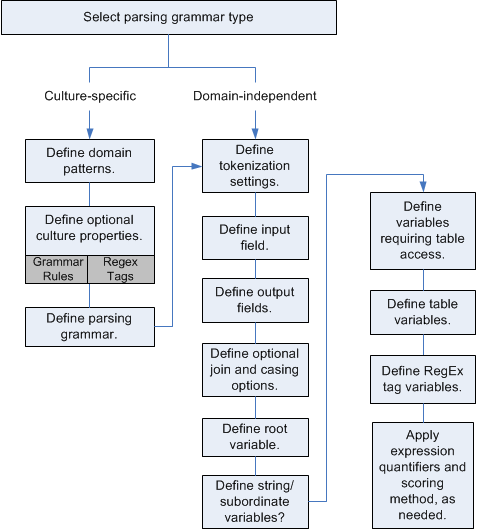
There are two kinds of grammars: culture specific and domain independent. A culture-specific parsing grammar is associated with a culture and/or language (such as English, Canadian English, Spanish, Mexican Spanish, and so on) and a particular type of data (phone numbers, personal names, and so on). When an Open Parser stage is configured to perform culture-specific parsing, each culture's parsing grammar is applied to each record. The grammar with the best parser score (or the first one to have a score of 100) is the one whose results are returned. Alternatively, culture-specific parsing grammars can use the value in the input record's CultureCode field and process the data according to the culture settings contained in the culture's parsing grammar. Culture-specific parsing grammars can inherit properties from a parent. A domain-independent parsing grammar is not associated with either a language or a particular type of data. Domain-independent parsing grammars do not inherit properties from a parent and ignore any CultureCode information in the input data.
Open Parser analyzes a sequence of characters in input fields and categorizes them into a sequence of tokens through a process called tokenization. Tokenization is the process of delimiting and classifying sections of a string of input characters into a set of tokens based on separator characters (also called tokenizing characters), such as space, hyphen, and others. The tokens are then placed into output fields you specify.
The following diagram illustrates the process of creating a parsing grammar: