Matching Records from One Source to Another Source
This procedure describes how to use an Interflow Match stage to identify records in one source that match records in another source. The first source contains suspect records and the second source contains candidate records. The dataflow only matches records from one source to records in another source. It does not attempt to match records from within the same source. The dataflow groups records into collections of matching records and writes these collections to an output file.
-
Drag a Match Key Generator stage onto the canvas and connect it to one of the source stages.
For example, if you are using a Read from File source stage, your dataflow would now look like this:
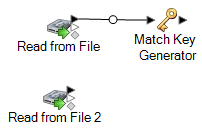
Match Key Generator creates a non-unique key for each record, which can then be used by matching stages to identify groups of potentially duplicate records. Match keys facilitate the matching process by allowing you to group records by match key and then only comparing records within these groups.
Note: You will add a second Match Key Generator stage later. For now you only need one on the canvas. -
Connect the copy of Match Key Generator to the other source stage.
For example, if you are using Read from File input stages your dataflow would now look like this:
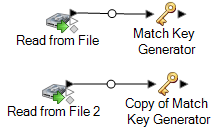
The dataflow now contains two Match Key Generator stages that produce match keys for each source using exactly the same rules. Having identically-configured Match Key Generator stages is essential to the proper functioning of this dataflow.
-
Drag an Interflow Match stage onto the canvas and connect each of the Match Key Generator stages to it.
For example, if you are using Read from File input stages your dataflow would now look like this:
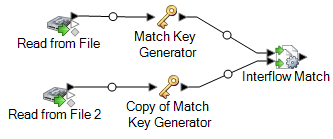
-
Drag a sink stage onto the canvas and connect it to the Interflow Match stage.
For example, if you were using a Write to File sink stage your dataflow would look like this:
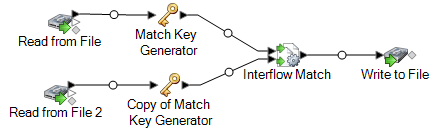
You now have a dataflow that will match records from two data sources.
Example of Matching Records from Multiple Sources
As a direct mail company, you want to identify people who are on a do-not-mail list so that you do not send direct mail to them. You have a list of recipients in one file, and a list of people who do not wish to receive direct marketing mail in another file (a suppression file).
The following dataflow provides a solution to this business scenario:
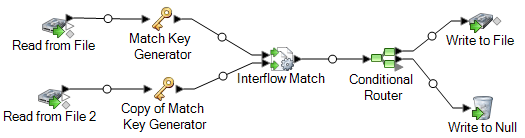
The Read from File stage reads data from your mailing list, and the Read from File 2 stage reads data from the suppression list. The two Match Key Generator stages are identically configured so that they produce a match key which can be used by Interflow Match to form groups of potential matches. Interflow Match identifies records in the mailing list that are also in the suppression file and marks these records as duplicates. Conditional Router sends unique records, meaning those records that were not found in the suppression list, to Write to File to be written out to a file. The Conditional Router stage sends all other records to Write to Null where they are discarded.