Splitter
A Splitter converts hierarchical data to flat data. Splitters have one input port and one output port that delivers data from the Splitter to the next stage. One way you could use the Splitter's functionality is to take a list of information in a file and extract each discrete item of information into its own data row. For example, your input could include landmarks within a certain distance of a latitudinal-longitudinal point, and the Splitter could put each landmark into a separate data row.
Using the Splitter Stage
- Under Control Stages, click the Splitter and drag it to the canvas, placing it where you want on the flow and connecting it to input and output stages.
- Double-click the Splitter. The Splitter Options dialog box appears.
- Click the Split at drop-down to see other list types available for
this stage. Click the list type you want the Splitter to create. The
Splitter Options dialog box will adjust accordingly with
your selection, showing the fields available for that list type.
Alternatively, you can click the ellipses (...) button next to the Split at drop-down. The Field Schema dialog box appears, showing the schema for the data coming into the Splitter. The list types are shown in bold, followed by the individual lists for each type. Also shown is the format of those fields (string, and double, for instance). Click the list type you want the Splitter to create and click OK. The Splitter Options dialog box will adjust accordingly with your selection, showing the fields available for that list type.
- Click Output header record to return the original record with the split list extracted.
- Click Only when input list is empty to return the original record only when there is no split list for that record.
- Select which fields you want the Splitter to include on output by checking the Include box for those fields.
- Click OK.
Splitter Example
This example takes output from a routing stage that includes driving directions and puts each direction (or list item) into a data row. The flow looks like this:

The flow performs the function as follows:
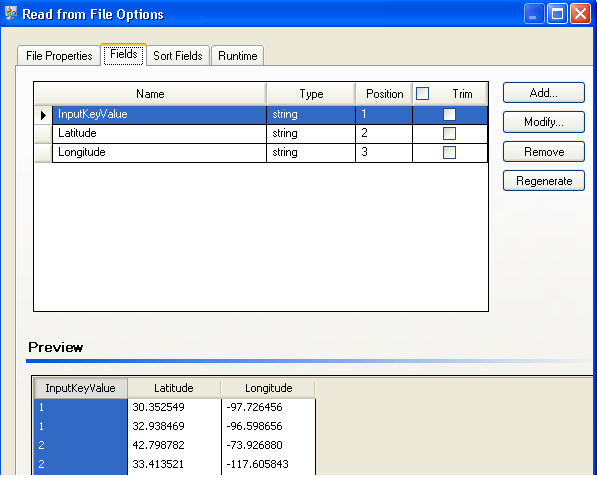
- The Read from File stage contains latitudes, longitudes,
and input key values to help you identify the individual points.
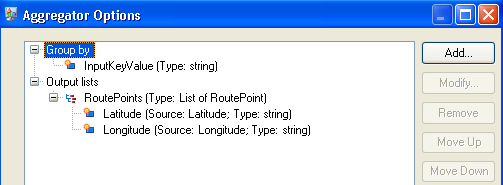
- The Aggregator stage builds up the data from the Read from File stage into a
schema (a structured hierarchy of data) and identifies the group of latitudes
and longitudes as a list of route points, which is a necessary step for the next
stage to work correctly.
- Spectrum Spatial Get Travel Directions stage creates directions from one location to another using the route points from step 2.
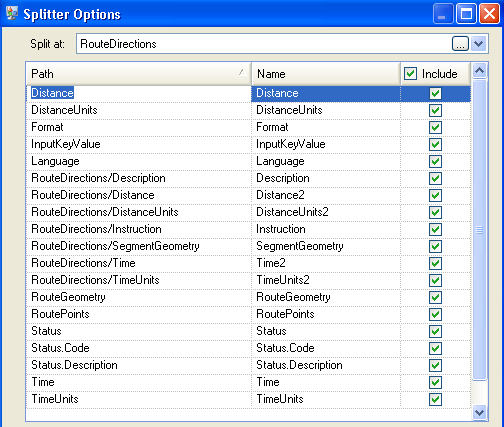
- The Splitter stage establishes that the data should be
split at the Route Directions field and that the output lists should include all
of the possible fields from the Get Travel Directions stage.
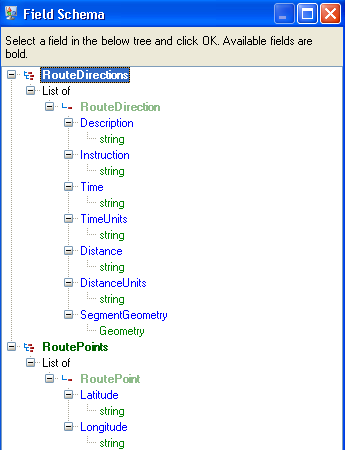
The schema is structured as follows, with Route Directions and Route Points being the available list types for this job:
- The Write to File stage writes the output to a file.