Leave Ignore constant fields checked to skip fields that
have the same value for each record.
Leave Compute p values checked to calculate p values for
the parameter estimates.
Leave Remove collinear column checked to automatically remove collinear columns during model building.
This option must be checked if Compute p values is also checked.
This will result in a 0 coefficient in the returned model.
Leave Include constant term (Intercept) checked to
include a constant term (intercept) in the model.
This field must be checked if Remove collinear column
is also checked.
Select a Solver from the dropdown list.
Solver
Description
Auto
Solver will be determined based on input data and parameters.
CoordinateDescent
IRLSM with the covariance updates version of cyclical coordinate
descent in the innermost loop.
CoordinateDescentNaive
IRLSM with the naive updates version of cyclical coordinate descent
in the innermost loop.
IRLSM
Ideal for problems with a small number of predictors or for Lambda
searches with L1 penalty.
L_BFGS
Ideal for datasets with many columns.
Note:CoordinateDescentNaive and CoordinateDescentNaive are currently
experimental.
Leave Seed for N fold checked and enter a seed number to
ensure that when the data is split into test and train data it will occur the
same way each time you run the dataflow. Uncheck this field to get a random
split each time you run the flow.
Check N fold and enter the number of folds if you are
performing cross-validation.
Check Fold assignment and select from the drop-down list
if you are performing cross-validation.
Fold assignment
Description
Auto
Allows the algorithm to automatically choose an option; currently
it uses Random.
Modulo
Evenly splits the dataset into the folds and does not depend on
the seed.
Random
Randomly splits the data into nfolds pieces; best for large datasets.
Stratified
Stratifies the folds based on the response variable for
classification problems. Evenly distributes observations from
the different classes to all sets when splitting a dataset into
train and test data. This can be useful if there are many
classes and the dataset is relatively small.
This field is applicable only if you
entered a value in N fold and Fold
field is not specified.
If you are performing cross-validation, check Fold field
and select the field that contains the cross-validation fold index assignment
from the drop-down list.
This field is applicable only if you did not enter a value in N
fold and Fold assignment.
Check Maximum iterations and enter the number of
training iterations that should take place.
Check Objective epsilon and enter the threshold for
convergence; this must be a value between 0 and 1.
If the objective value is
less than this threshold, the model will be converged.
Check Beta epsilon and enter the threshold for
convergence; this must be a value between 0 and 1.
If the objective value is
less than this threshold, the model will be converged. If the L1 normalization
of the current beta change is below this threshold, consider using
convergence.
Select the Regularization type you want to use.
Regularization type
Description
LASSO (Least Absolute Shrinkage and Selection Operator)
Selects a small subset of variables with a value of lambda high enough to be considered crucial. May not perform well when there are correlated predictor variables, as it will select one variable of the correlated group and remove all others. Also limited by high dimensionality; when a model contains more variables than records, LASSO is limited in how many variables it can select. Ridge Regression does not have this limitation. When the number of variables included in the model is large, or if the solution is known to be sparse, LASSO is recommended.
Ridge Regression
Retains all predictor variables and shrinks their coefficients proportionally. When correlated predictor variables exist, Ridge Regression reduces the coefficients of the entire group of correlated variables towards equaling one another. If you do not want correlated predictor variables removed from your model, use Ridge Regression.
Elastic Net
Combines LASSO and Ridge Regression by acting as a variable selector while also preserving the grouping effect for correlated variables (shrinking coefficients of correlated variables simultaneously). Elastic Net is not limited by high dimensionality and can evaluate all variables when a model contains more variables than records.
A common concern in predictive modeling is overfitting, when an analytical model corresponds too closely (or exactly) to a specific dataset and therefore may fail when applied to additional data or future observations. Regularization is one method used to mitigate overfitting.
Check Value of alpha and change the value if you do not
want to use the default of .5.
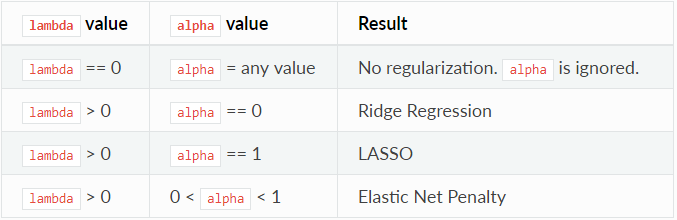
The alpha parameter controls the distribution
between the ℓ1 and ℓ2 penalties. Valid values range between 0 and 1; a value of
1.0 represents LASSO, and a value of 0.0 produces ridge regression. The table
below illustrates how alpha and lambda affect regularization.
Note: The single equals sign is an assignment operator meaning "is," while the
double equals sign is an equality operator meaning "equal
to."
Check Value of lambda and specify a value if you do not
want Logistic Regression to use the default method of calculating the lambda
value, which is a heuristic based on training data.
The lambda parameter controls the amount of regularization applied. For example, if lambda is 0.0,
no regularization is applied and the alpha parameter is ignored.
Check Search for optimal value of lambda to have
Logistic Regression compute models for full regularization path.
This starts at lambda max (the highest lambda value that makes sense—that is, the lowest value
driving all coefficients to zero) and goes down to lambda min on the log scale,
decreasing regularization strength at each step.
The returned model will have
coefficients corresponding to the optimal lambda value as decided during
training.
Check Stop early to end processing when there is no more
relative improvement on the training or validation set.
Check Maximum lambdas to search and enter the maximum
number of lambdas to use during the process of lambda search.
Check Maximum active predictors and enter the maximum
number of predictors to use during computation.
This value is used as a stopping criterion to prevent expensive model building with many predictors.
Click OK to save the model and configuration or continue to the next tab.
 Note: The single equals sign is an assignment operator meaning "is," while the double equals sign is an equality operator meaning "equal to."
Note: The single equals sign is an assignment operator meaning "is," while the double equals sign is an equality operator meaning "equal to."