Distributed processing takes parts of your flow and distributes the processing of
those parts to a cluster of Spectrum Technology Platform servers. For example,
your flow may perform geocoding, and you might want to distribute the geocoding
processing among several Spectrum Technology Platform nodes in a cluster to
improve performance.
Decide which stages of your flow you want to distribute, then create a
subflow containing the stages that you want to distribute.
Do not use these stages in a subflow that will be used for distributed
processing:
Sorter
Unique ID Generator
Record Joiner
Interflow Match
These sets of stages must be used together in a subflow for distributed
processing:
Matching stages (Intraflow Match and Transactional Match) and
consolidation stages (Filter, Best of Breed and Duplicate
Synchronization).
Aggregator and Splitter
Do not include other subflows within the subflow (nested subflows).
Note these exceptions if you will be performing matching operations in a
subflow used for distributed processing:
Sorting must be done in the job and not in the subflow. You must turn
sort off in the stage and put the sort at job level.
Match Analysis is not supported in a distributed subflow
Collection numbers will be reused within a microflow batch group
Using a Write Exception stage in a subflow may produce unexpected results.
Instead, you should add this stage to your flow at the job level.
Once you have created your subflow for the portion of the flow you want to
distribute, add the subflow to the parent flow and connect it to an upstream
and downstream stage. Subflows used for distributed processing may have only one
input port.
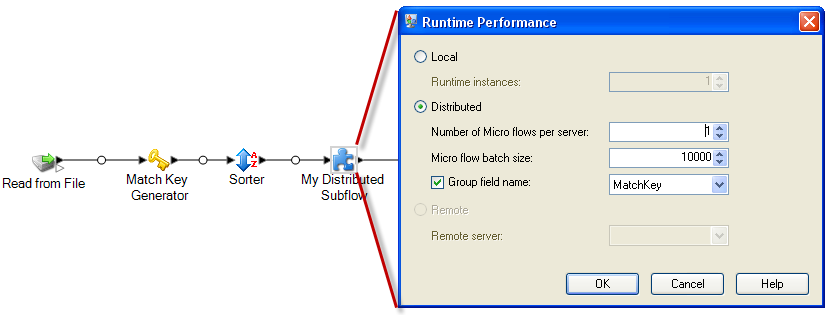
Right-click the subflow and select Options.
Select Distributed.
Enter the number of microflows to be sent to each server.
Enter the number of records that should be in each microflow batch.
Optional: (Optional) Check Group field name and select the name of
the field by which the microflow batches should be grouped.
If you provide a group field, your batch sizes could be greater than the
number you specified in the Micro flow batch size
field because a group will not be split across multiple batches. For
example, if you specify a batch size of 100, but you have 108 records within
the same group, that batch will include 108 records. Similarly, if you
specify a batch size of 100, and a new group of 28 records with the same ID
starts at record 80, you will have 108 records in that batch.
This example shows a flow where a subflow named My Distributed
Subflow has been configured to run in distributed mode: