Read from DB
- Connectivity to Hive from Spectrum on Windows
- Support and connectivity to Hive version 2.1.1 from Spectrum with high availability
- Support to Read and Write from Hive DB (JDBC) via Model Store connection
Also see Best Practices for connecting to HDFS 3.x and Hive 2.1.1.
To use the Read from DB stage, you need to create connection to the respective database usingData Sources page in the Spectrum Management Console. For details on configuring new connections, see Connections.
Using Read from DB stage
- On the Spectrum Flow Designer Home page, click New.
- On the New Flow page, click Job, Service, or Subflow, as required and then click the corresponding blank canvas.
- Click OK.
- In the dialog box that appears, give a name to the Flow, Job, Service, or Subflow you are creating.
- Click OK.
- From the Palette Panel, drag the Read from DB stage to the canvas.
- Connect the required dataflow stage to the output and configure it. Note: For details on how to configure the Sources and the Sinks stages, see the respective sections.
- Click Read from DB and configure the stage as described in the following sections.
General Tab
|
Field Name |
Description |
|---|---|
|
Connection |
Select the database connection you want to use. Your choices vary depending on what connections are defined in the Spectrum Management Console. The dropdown displays all
the connections you have configured. To configure a new connection or edit any
existing connections, click the Manage Connections link. It
takes you to the Connections page in the
Spectrum Management Console. For details on configuring new
connections, see Connections.
Note: Click the Refresh  icon to update any modification, deletion or addition
to your list of connections. icon to update any modification, deletion or addition
to your list of connections. |
|
SQL |
Enter the SQL query to specify the records that need
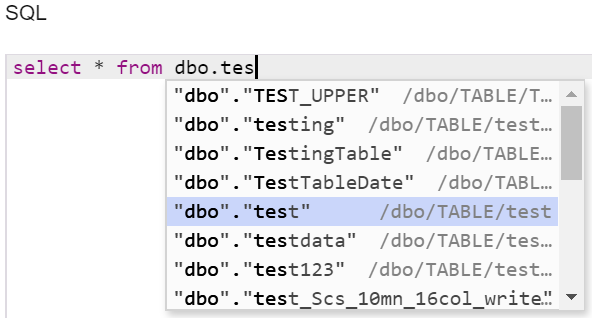
to be read from the data source on running the dataflow. The SQL field helps you to write the SQL queries faster by reducing the typing effort and providing a quick access to the syntax information by listing all keywords, snippets and database objects. For example, if you start to type a new SQL query
like the query shown below, you see a list of all the keywords,
snippets and database objects that match the written prefix. The
suggestions are displayed automatically. As you type, the
suggestions are filtered to match the typed
characters. Note: This auto-suggestion feature is also
supported while building complex queries in Visual Query
Builder.
Note: The
auto-suggestions are always generated with double quotes against
the tables and fields. But, these may vary with databases; for
example, MySQL uses ticks `dbo`.`test` which
you may have to update manually with ticks. The SQL query can include variables instead of actual column names. Using variables allows you to customize the query at runtime. For more information, see Query Variables. A sample query for exposing BranchID and
BranchType from public.Branch
table in the database can be:
Note: For
Integer type fields, values can be entered
without quotes, but for String type, it should
be in single quotes. |
| Build SQL | Create a complex query by selecting multiple
columns, creating joins, and nested queries by clicking
Build SQL, which opens the
Visual Query Builder. For more information,
see Visual Query Builder. Note: A query created using the Visual Query Builder is
displayed with fully qualified names of columns and tables and
double quotation mark (") as opening and closing character to
the database object names in the SQL
field. For MySQL database, the queries are generated with ticks
only. |
| Generate Schema | To see the schema of the data to be fetched by the
query, click Generate Schema. If you edit an existing query, click Generate Schema to fetch the modified schema. Note: On clicking
Generate Schema, the entity names in
the SQL query are retained and not replaced with their fully
qualified names. |
| Preview | To see a sample of the records fetched by the SQL query, click Preview. |
date datatype as String values. This is the
behavior of the jTDS driver, which is the default driver used by
Spectrum. To handle all date datatype values as is, use Microsoft's
JDBC driver.Runtime Tab
| Field name | Description |
|---|---|
| Fetch size |
Select this option to specify the number of records to read from the database table at a time. For example, if the Fetch size value is 100 and total number of records to be read is 1000, then it would take 10 trips to the database to read all the records. Setting an optimum fetch size
can improve performance significantly.
Note: You can calculate an
optimum fetch size for your environment by testing the execution
times between a Read from DB stage and a Write to Null stage.
For more information, see Determining an Optimimum Fetch Size.
|
| Stage Options |
This section lists the dataflow options used in the SQL query of this
stage and allows you to provide a default value for all these
options. The Name column lists the options
while you can enter the default values in the corresponding
Value column.
Note: The default value
provided here is also displayed in the Map dataflow
options to stages section of the
Dataflow Options dialog box. The
dialogue box also allows you to change the default value. In
case of a clash of default values provided for an option through
Stage Options, Dataflow
Options, and Job Executor
the order of precedence is: Value provided through
Job Executor > Value defined through
the Dataflow Options dialogue box > Value
entered through the Stage
Options. |