Profiling Rules
Profiling rules perform different types of analysis on your data. When setting up a profile, choose the profiling rules that perform the types of data analysis you are interested in.
This section describes the profiling rules supported in Spectrum Discovery.
Character Analysis
This rule identifies patterns, scripts, and character types in string fields. To
configure this rule when creating a profile, click the Configure icon ![]() and add, edit, or delete special characters from the
prepopulated list. When you enable this rule, you will get this information for the
string fields in your data:
and add, edit, or delete special characters from the
prepopulated list. When you enable this rule, you will get this information for the
string fields in your data:
- Frequency: The most-used phrases in the selected string column.
- Scripts Distribution: The different scripts identified in the selected string column and their count.
- String Lengths: The distribution of string lengths in the selected string column.
- Character Categories: The types of characters in the selected column, such as letter, punctuation, and number.
- Text Patterns: Converts data in the string column to pattern
and displays the pattern, its count, and percentage occurrence. The pattern is
determined using this rule:
- Latin upper-case characters are replaced with "A"
- Latin lower-case characters are replaced with "a"
- Digits are replaced with "9"
- Control characters are replaced with
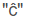
Custom Pattern Analysis
This rule identifies any pattern in the string column. You can configure as many regular
expressions as you want to match your data against. To configure this rule when creating
a profile, click the Configure icon ![]() , and enter these details:
, and enter these details:
- Key: Name of the pattern to be identified
- Value: The regular expression for the pattern
For example, if you want to identify email addresses in string columns, enter the regular expression
^(.+)@(.+)$in the Value field and email in the Key field. - To add another expression, click the Add icon and add details of the next key value pair. You can add as many expressions as you would like to match the data against.
When you enable this rule, you will get this information:
- Validity: The values that matched at least one of the regular expression patterns in the rule.
- Pattern Match Distribution: The distribution of records that matched the regular expressions.
Internal Rule
Determines statistics, such as completeness, uniqueness, frequency and outliers in the data set.
Semantic Analysis
- User Defined: This rule detects the user-defined semantic types in the
Define Glossary and uses it to profile the data set. The
user-defined semantic types can find out data based on these parameters:
- If you defined an expression in the semantic type, it finds out its match in the data set and gets the result on the Data Profiling Results page.
- If you specified the data to be looked for, the user-defined semantic type looks for it in the data set and presents it on the Data Profiling Results page. For example, if Single, Married is specified in the Exists In option of the semantic type, it will fetch all the records that have these value.
- Advanced Transformer Look-up: This rule determines the
user-defined tables in the Advanced Transformer stage and uses it to profile the data
set. To run this rule, you need to install Spectrum Data Normalization and load the
Advanced Transformer reference tables. The tables you configure appears in the
Semantic Type tab on the Define
Glossary page, which are non-editable. Note: You can edit the tables in Enterprise Designer or Flow Designer.
If you select this rule, the Data Profiling Results page displays the detected semantic types if the data matches with the table defined in the stage.
- Open Parser Look-up: This rule determines the user-defined
tables in the Open Parser stage and uses it to profile the data set. To run this
rule, you need to install Spectrum Data Normalization and load the Open Parser
reference tables. The tables you configure appears in the Semantic
Type tab on the Define Glossary page, which are
non-editable.Note: You can edit the tables in Enterprise Designer or Flow Designer.
If you select this rule, the Data Profiling Results page displays the detected semantic types if the data matches with the table defined in the stage.
- Credit Card Validation Analysis: Select this rule to detect and validate
credit card numbers and identify credit card numbers as JCB, VISA, Diners Club
(DINERS), MasterCard, Discover, or American Express (AMEX). If you select this rule,
the Data Profiling Results page displays an additional Credit
Card Summary tab showing these details:
- Validity: The valid and invalid credit card numbers.
- Credit Card Distribution: Category-wise distribution of the detected credit cards
- Date Analysis: This rule detects and validates dates in string columns. It
also identifies date patterns in the columns and their distribution. This analysis
can be useful in detecting date entries in erroneous columns, for example in email
data. If you select this rule, Data Profiling Results page displays an additional
Date Summary tab for the string columns that have dates. This tab shows these
details:
- Validity: The valid and invalid values.
- Date Patterns: The date patterns detected in the selected columns, their total count, and percentage of that pattern in the data set.
-
Email Analysis: This rule detects and validates the email addresses and
determines the distribution of email domains in the selected data column. If you
select this rule, Data Profiling Results page displays an additional Email Summary
tab showing these details:
- Validity: The valid and invalid values.
- Domain Distribution: The top ten email domains in the selected data column.
- Phone Number Analysis: Select this rule to detect and validate phone numbers
and identify phone numbers as fixed line numbers, mobile numbers, or any other type
of number. This rule also gives the distribution of the phone numbers by country and
region. You need to configure this rule to define the default country to use when a
phone number does not have a country code. If you select this rule, Data
Profiling Results page displays an additional Phone Number
Summary tab showing these details:
- Validity: The valid and invalid phone numbers.
- Phone Number Types: The types of phone numbers, such as mobile, land line, fixed line, VOIP, Pager, voice mail, or toll-free.
- Phone Numbers by Country: The country-wise distribution of the detected phone numbers.
- Phone Numbers by Region: The region-wise distribution of the detected phone numbers
- Vehicle Identification Number (VIN) Analysis: Select this rule to detect and
validate vehicle identification numbers. This rule also gives the distribution of
Vehicle Identification Numbers by country. If you select this rule, the
Data Profiling Results page displays an additional
VIN Summary tab showing these details:
- Validity: The valid and invalid vehicle identification numbers.
- VIN Country Distribution: Country-wise distribution of the detected vehicle identification numbers.
- Social Security Number (SSN) Analysis: Select this rule to detect and validate social security numbers. If you select this rule, the Data Profiling Results page displays an additional SSN Summary tab showing the valid and invalid social security numbers.
- International Bank Account Number (IBAN) Analysis: Select this rule to detect
and validate international bank account numbers. This rule also gives the
distribution of International Bank Account Numbers by country. If you select this
rule, the Data Profiling Results page displays an additional
IBAN Summary tab showing these details:
- Validity: The valid and invalid international bank account numbers.
- IBAN Country Distribution: Country-wise distribution of the detected international bank account numbers.
- Semantic Analysis: Select this rule to detect semantic types, such as first name, city, country, ISO country code 2 and 3, last name (family name), and states. This rule can help find values in incorrect columns, such as city names in a Country column. If you select this rule, the Data Profiling Results page displays an additional Semantic Type tab showing the detected semantic types and their frequency.
- U.S. Address Analysis: This rule determines the quality of your address data
using the U.S. database of Spectrum Universal Addressing. To run this rule, you need
to:
- Install the Spectrum Universal Addressing U.S. database and define it as a resource in Management Console. For more information about adding this database resource, the Administration Guide.
- Configure the U.S. Address Analysis rule by clicking the Configure button
 and entering this information:
and entering this information:- US Address Coder database: Select the Spectrum Universal Addressing database resource configured in Management Console.
- AddressLine1 field to AddressLine5 field: Map these fields to the columns of the table you are analyzing. You do not necessarily need to enter column names in all the fields. However, the more specific you are the better the matching score will be.
- Map the columns from your table to the City,
Country, USUrbanName,
FirmName field,
PostalCode, and
StateProvince fields.
If you select this rule, the Data Profiling Results page shows the Address Summary tab.
- The legend below the chart shows the match score for the data along with the color coding.
- Point anywhere in the graph area to view the match score. The scores are in ranges (0, 1-25, 26-50, 51-80, 81-99, and 100), with zero representing no match of the data to the database. The graph also shows the percentage of matching records detected (color coded).
- Click the area in the graph to view the data that matched or did not match to the database.
- International Address Analysis: This rule determines the quality of your
address data using the Spectrum Global Address Validation database. To run this
rule, you need to:
- Install the Spectum Global Address Validation database and define it as a resource in Management Console. For more information, see the Administration Guide.
- Configure the International Address Analysis rule by clicking the Configure
button , and entering this information:
- Addressing Engine Database: Select the Global Address Validation database resource configured in the Management Console.
- Confidence Threshold: Enter the value of confidence threshold to detect fields falling below the specified value. The default value of this field is 80.
- Table List: Select the table on which you would like to run this rule.
- AddressLine1 field and Country field: Map these fields to the columns in the table you are analyzing.
- Map the columns from your table to the LastLine,
City, CitySubdivision,
PostalCode, State,
StateSubdivision, and
FirmName fields. You do not necessarily need to
enter column names in all the fields. However, the more specific you are
the better the matching score will be.If you select this rule, the Data Profiling Results page shows and Address Summary tab, which displays:
- International Address Confidence Distribution: The match score for the data. The score is color coded. Point anywhere in the donut chart to view the score range (0, 1-25, 26-50, 51-80, 81-99, and 100), with zero representing no match of the data in the database. Click the area in the chart to preview the matching or non-matching data.
- International Address Precision: This distribution of validation levels of addresses, such as state, house, postal code, city, city sub-division, and street.
- International Address Mismatched Fields Distribution: The distribution of mismatched fields of addresses, such as City Subdivision, State Province, Street Name, and Postal Code are displayed here. The confidence threshold of this address is less than the value defined by you while configuring the International Address Analysis rule.
Service Configuration
Use this to consume the default Spectrum services and the services you have configured using the different Spectrum stages you licensed for. This configuration helps you reuse the transformations designed with various Spectrum stages on your data. Let us understand it with this example.
- Select the Service Configuration rule, and click the
corresponding gear icon
 .
. - In the Service Configuration pop-up, specify these
details.
Field Description Services From the drop down list, select the required service. It lists all the exposed services. Note: You can add multiple services by clicking the Add Services link.Service input fields and Source input fields Displays the list of the fields used as input in the selected service. Every Service input field has a corresponding Source input fields. Use the Source input fields drop-down list to select the required field from your input data. Data in the selected field will be used as input when you run profile.Note: The data types of input fields and source fields with which those are mapped should be the same.Example:- The Service input fields are First_Name and Last_Name.
- In the corresponding Source input fields, you select FirstName and LastName.
Service output fields Shows the output fields in the selected service. Select the fields that you want in your profile output. You can use the type-ahead search box to find out the required fields. Note: If the service has List data type as output, you can't use that in profiling. - Click OK.
- When you run profiling, the output will be displayed on the Data Profiling
Results page under Name_Service. Click on any of the output
fields to view the related statistics. Note: You can use the services and obtain profiling outputs even if you do not have a license for the respective module or your license has expired. The Profile Summary page will have an additional tab to indicate the license exception.