Exemple XML
Configuration de Read from XML
Le flux de données Write to Hub qui utilise un fichier XML pour l'entrée ressemble à cela :
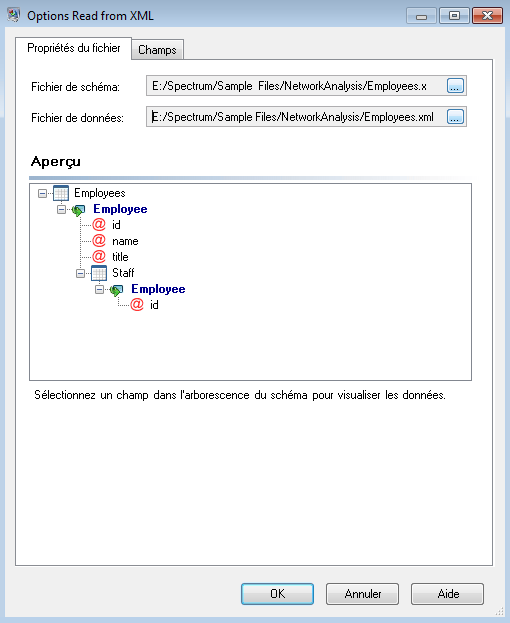
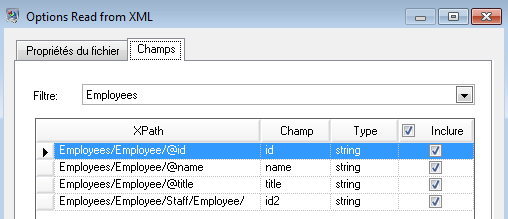
Le stage Read from XML utilise un fichier hiérarchique qui contient les éléments suivants :

Le stage Read from XML apparaît comme suit lorsqu'il est configuré pour fonctionner avec ce fichier d'entrée :
Ensuite, nous configurons le stage Write to Hub. Après avoir nommé le modèle « Employés », nous configurons le stage pour inclure les entités et relations qui composent le modèle.
Dans la mesure où nous créons un modèle semblable à un organigramme, nos entités sont des employés auxquels des ID numériques sont affectés. Dans la boîte de dialogue Ajouter une entité, nous commençons par cliquer sur le bouton Parcourir pour accéder à la boîte de dialogue Schéma de champ, puis nous sélectionnons « ID ». Il s'agit du premier groupe d'entités dans notre modèle.
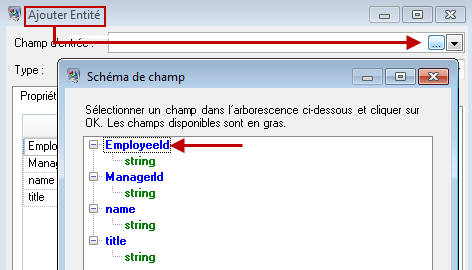
Ensuite, nous définissons le champ Type sur « Employé » et cochons les cases « nom » et « titre » car nous souhaitons reprendre ces champs comme des propriétés pour les entités ID dans le modèle.
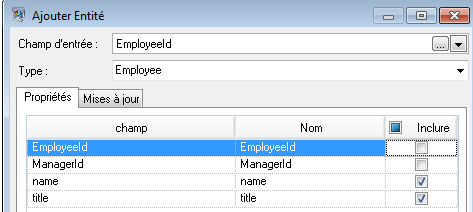
Après avoir défini les propriétés pour l'entité ID, nous configurons les options de traitement. L'onglet Mises à jour vous permet d'indiquer si les propriétés peuvent être mises à jour dans le modèle une fois en place et si elles doivent écraser les données existantes. Par exemple, dans ce cas-ci, Mary Hansen ressortirait deux fois car pour l'ID 2, c'est une employée mais, pour l'ID 11, c'est une responsable. Lorsque Write to Hub traite Mary pour la seconde fois, il pourrait écraser ou supprimer les données renseignées à la suite du premier traitement de Mary. En sélectionnant Ne jamais écraser les propriétés avec des données vides (valeur par défaut), toute mise à jour créera de nouvelles propriétés et écrasera les propriétés existantes, mais elle n'effacera pas les propriétés définies par le premier traitement mais manquantes dans le second traitement. Cela garantit également que l'ordre dans lequel ces enregistrements sont lus n'a aucun impact sur le modèle.
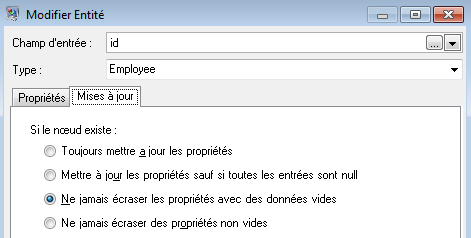
Si nous sélectionnions Toujours mettre à jour les propriétés, les données seraient toujours écrasées et seul le dernier ensemble de données de propriété serait reflété dans le modèle. Si nous sélectionnions Mettre à jour les propriétés sauf si toutes les entrées sont nulles, les données seraient toujours écrasées sauf si chaque champ dans le nouvel enregistrement était vide. Enfin, si nous sélectionnions Ne jamais écraser les propriétés non vides, le premier ensemble de données de tout champ donné serait conservé, sauf si ce champ était vide. Dans ce cas-là, le premier ensemble de données non vides serait conservé.
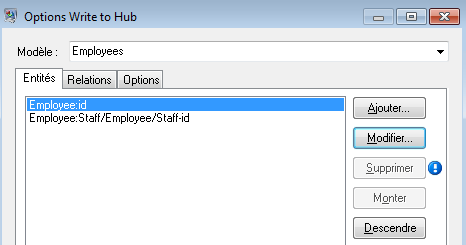
Nous répétons ces étapes pour ajouter « ID du responsable » comme second groupe d'entités dans notre modèle. Bien qu'ID du responsable et ID d'employé soient des champs différents dans le fichier d'entrée, les types des deux entités sont définis sur « Employé ». Si nous définissons ID du responsable sur un autre type, le modèle contiendrait deux entités pour les responsables de niveau moyen. Par exemple, Jim Waterman disposerait d'une entité comme employé et d'une entité comme responsable. Si les deux entités sont définies sur le type « Employé », les responsables de niveau moyen, tels que Jim, disposeraient d'une seule entité dans le modèle. Cette entité présenterait d'autres entités arrivant dans celle-ci (des employés) et une autre entité sortant de celle-ci (vers leur responsable respectif). Nous n'ajoutons pas de propriétés aux entités ID du responsable car les valeurs dans ces champs (nom, titre) s'appliquent aux employés et non aux responsables. Par ailleurs, nous acceptons la sélection par défaut de l'option Ne jamais écraser les propriétés avec des données vides dans l'onglet Mises à jour.
L'onglet Entités complété pour cet exemple apparaît comme suit :
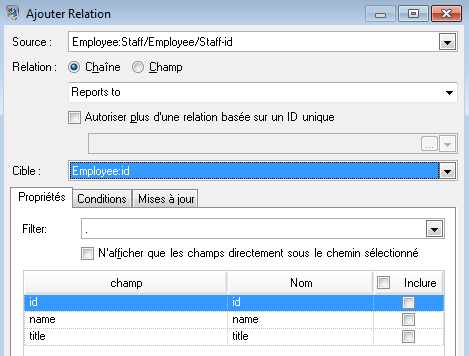
Désormais, nous configurons l'onglet Relations. La première chose que nous faisons dans la boîte de dialogue Ajouter une relation est de sélectionner la source de la relation à partir de la liste des entités créées dans l'onglet Entités. La relation entre nos entités reflète la structure de reporting (employé vers responsable) ; par conséquent, nous sélectionnons l'entité « Employé:Personnel/Employé/ID de personnel » comme source. Ensuite, nous sélectionnons « Chaîne » comme nom de la relation et nous saisissons le texte « Relève de ». Après cela, nous sélectionnons la cible de la relation dans la liste des entités créées dans l'onglet Entités ; pour notre exemple, nous sélectionnons « Employé:ID ». Si nous utilisions une relation « gère » au lieu d'une relation « relève de », nous inverserions les sélections dans les champs source et cible.
L'onglet Relations complété pour cet exemple apparaît comme suit :
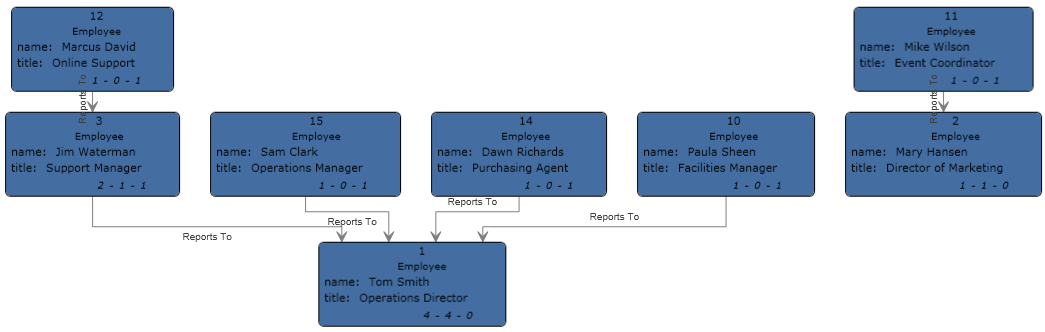
La configuration de ce flux de données est complète et génère le modèle suivant, comme décrit dans le Relationship Analysis Client :
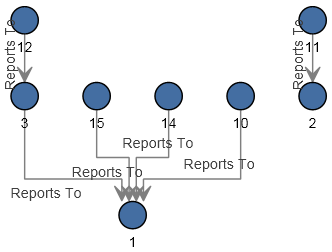
Tout comme pour l'exemple plat, ce modèle peut être affiché dans le style Panneau, comme indiqué ci-dessous.