Uso de una memoria caché global para las consultas
Si tiene una tabla de grandes dimensiones, puede cargar los datos de la tabla de dimensiones en una memoria caché, y utilizarla para buscar claves de reemplazo. Usar una memoria caché mejora el rendimiento, en comparación con la búsqueda directa en la tabla de dimensiones mediante la base de datos de consulta.
Para utilizar una memoria caché debe crear dos flujos de datos: uno para llenar la memoria caché con los datos de la tabla de dimensiones y otro que utilice la memoria caché durante la actualización de la tabla de hechos. El siguiente diagrama ilustra cómo los dos flujos trabajar juntos:
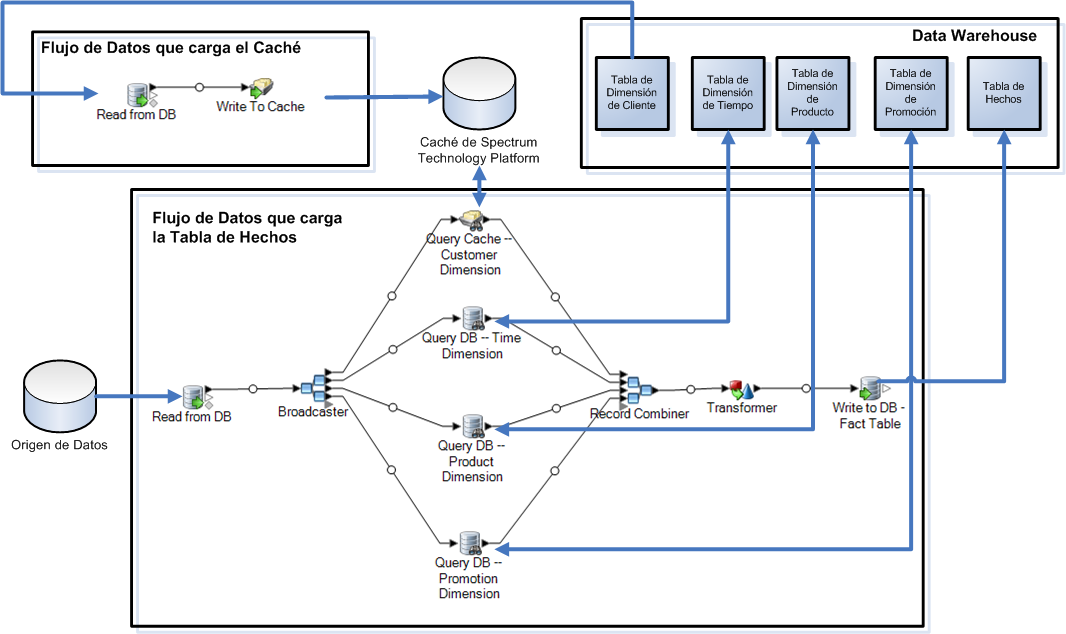
Si desea asegurarse de que la memoria caché se llena con los datos más recientes de la tabla de dimensiones cada vez que actualiza la tabla de hechos, puede crear un flujo de proceso que primero ejecute el trabajo para llenar la tabla de dimensiones y, a continuación, ejecute el trabajo para actualizar la tabla de hechos. Esto le permite activar el flujo de proceso con el fin de ejecutar los flujos de datos en sucesión. Para obtener más información sobre los flujos de proceso, consulte la Guía del diseñador de flujo de datos.