Utilisation d'un cache global pour les requêtes
Si vous disposez d'une table de dimensions volumineuse, vous pouvez charger les données de cette table dans un cache et utiliser ce dernier pour rechercher des clés de substitution. L'utilisation d'un cache améliore les performances par rapport aux recherches directes dans la table de dimensions à l'aide de Query DB.
Pour utiliser un cache, vous devez créer deux flux de données : l'un pour renseigner le cache à l'aide de données provenant de la table de dimensions, et l'autre pour utiliser le cache lors de la mise à jour de la table de faits. Le diagramme suivant montre comment les deux flux de travail fonctionnent ensemble :
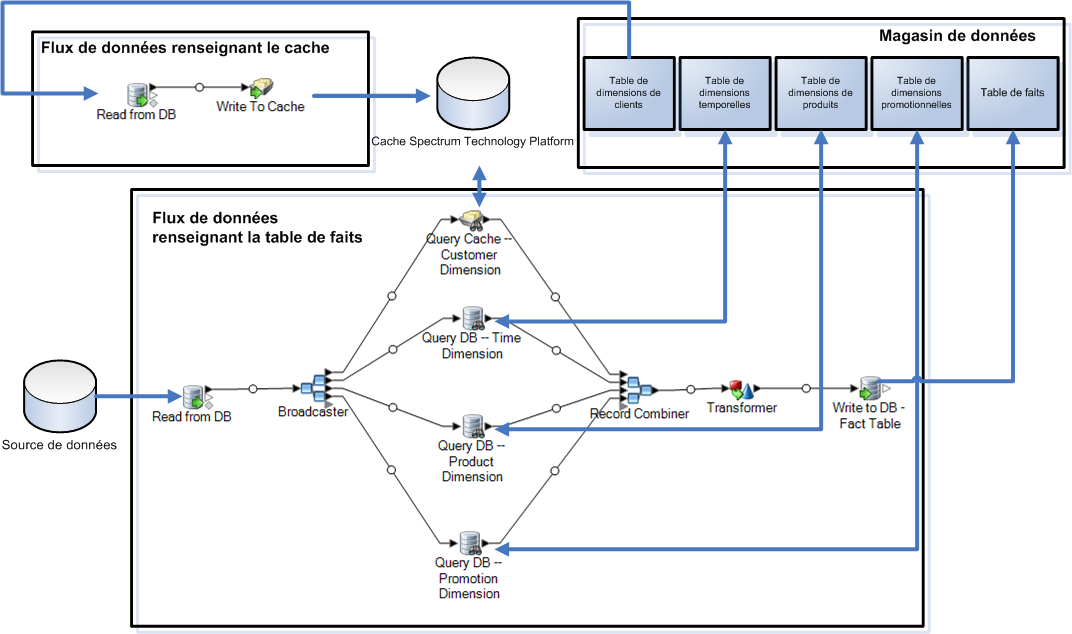
Si vous souhaitez vérifier que le cache est renseigné à l'aide des données les plus récentes de la table de dimensions chaque fois que vous mettez à jour votre table de faits, vous pouvez créer un flux de processus qui exécute d'abord le job de renseignement de la table de dimensions, puis le job de mise à jour de la table de faits. Cela vous permet d'exécuter le flux de processus de sorte que les deux flux de données se suivent. Pour plus d'informations sur les flux de processus, reportez-vous au Guide de Dataflow Designer.