
Parsing Arabic Names
This template demonstrates how to parse westernized Arabic names into component parts. The parsing rule separates each token in the Name field and copies each token to five fields: Kunya, Ism, Laqab, Nasab, Nisba. These output fields represent the five parts of an Arabic name and are described in the business scenario.
Business Scenario
You work for a bank that wants to better understand the Arabic naming system in an effort to improve customer service with Arabic-speaking customers. You have had complaints from customers whose billing information does not list the customer's name accurately. In an effort to improve customer intimacy, the Marketing group you work in wants to better address Arabic-speaking customers through marketing campaigns and telephone support.
In order to understand the Arabic naming system, you search for and find these resources on the internet that explain the Arabic naming system:
Arabic names are based on a naming system that includes these name parts: Ism, Kunya, Nasab, Laqab, and Nisba.
- The ism is the main name, or personal name, of an Arab person.
- Often, a kunya referring to the person's first-born son is used as a substitute for the ism.
- The nasab is a patronymic or series of patronymics. It indicates the person's heritage by the word ibn or bin, which means son, and bint, which means daughter.
- The laqab is intended as a description of the person. For example, al-Rashid means the righteous or the rightly-guided and al-Jamil means beautiful.
- The nisba describes a person's occupation, geographic home area, or descent (tribe, family, and so on). It will follow a family through several generations. The nisba, among the components of the Arabic name, perhaps most closely resembles the Western surname. For example, al-Filistin means the Palestinian.
The following dataflow provides a solution to the business scenario:
This dataflow template is available in Enterprise Designer. Go to and select ParseArabicNames. This dataflow requires Data Normalization.
In this dataflow, data is read from a file and processed through the Open Parser stage. For each data row in the input file, this dataflow will do the following:
Read from File
This stage identifies the file name, location, and layout of the file that contains the names you want to parse. The file contains both male and female names.
Open Parser
This stage defines whether to use a culture-specific domain grammar created in the Domain Editor or to define a domain-independent grammar. A culture-specific parsing grammar that you create in the Domain Editor is a validated parsing grammar that is associated with a culture and a domain. A domain-independent parsing grammar that you create in Open Parser is a validated parsing grammar that is not associated with a culture and domain.
In this template, the parsing grammar is defined as a domain-independent grammar.
The Open Parser stage contains a parsing grammar that defines the following commands and expressions:
%Tokenizeis set to the space character (\s). This means that Open Parser will use the space character to separate the input field into tokens. For example, Abu Mohammed al-Rahim ibn Salamah contains five tokens: Abu, Mohammed, al-Rahim, ibn and Salamah.%InputFieldis set to parse input data from the Name field.%OutputFieldsis set to copy parsed data into five fields: Kunya, Ism, Laqab, Nasab, and Nisba.- The
<root>expression defines the pattern for Arabic names: - Zero or one occurrence of Kunya
- Exactly one or two occurrences of Ism
- Zero or one occurrence of Laqab
- Zero or one occurrence of Nasab
- Zero or more occurrences of Nisba
The rule variables that define the domain must use the same names as the output fields defined in the required OutputFields command.
The parsing grammar uses a combination of regular expressions and expression quantifiers to build a pattern for Arabic names. The parsing grammar uses these special characters:
- The "?" character means that a regular expression can occur zero or one time.
- The "*" character means that a regular expression can occur zero or more times
- The ";" character means end of a rule.
Use the Commands tab to explore the meaning of the other special symbols you can use in parsing grammars by hovering the mouse over the description.
By default, quantifiers are greedy. Greedy means that the expression accepts as many tokens as possible, while still permitting a successful match. You can override this behavior by appending a '?' for reluctant matching or '+' for possessive matching. Reluctant matching means that the expression accepts as few tokens as possible, while still permitting a successful match. Possessive matching means that the expression accepts as many tokens as possible, even if doing so prevents a match.
To test the parsing grammar, click the Preview tab. Type the names shown below in the Name field and then click Preview.
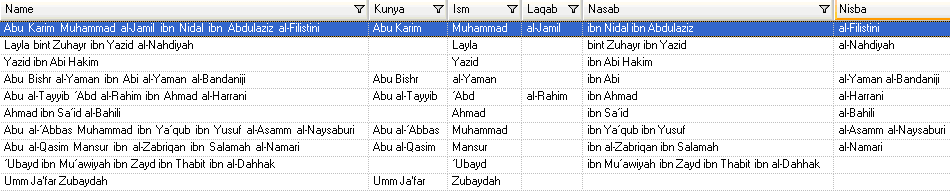
You can also type other valid and invalid names to see how the input data is parsed.
You can use the Trace feature to see a graphical representation of either the final parsing results or to step through the parsing events. Click the link in the Trace column to see the Trace Details for the data row.
Write to File
The template contains one Write to File stage. In addition to the input field, the output file contains the Kunya, Ism, Laqab, Nasab, and Nisba fields.