
Parsing Chinese Names
This template demonstrates how to parse Chinese names into component parts. The parsing rule separates each token in the Name field and copies each token to two fields: LastName and FirstName.
Business Scenario
You work for a financial service company that wants to explore if it is feasible to include the Chinese characters for its Chinese-speaking customers on various correspondence.
In order to understand the Chinese naming system, you search for and find this resource on the internet, which explains how Chinese names are formed:
en.wikipedia.org/wiki/Chinese_names
The following dataflow provides a solution to the business scenario:
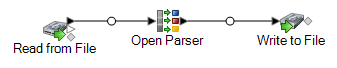
This dataflow template is available in Enterprise Designer. Go to and select ParseChineseNames. This dataflow requires Data Normalization.
In this dataflow, data is read from a file and processed through the Open Parser stage. For each data row in the input file, this data flow will do the following:
Read from File
This stage identifies the file name, location, and layout of the file that contains the names you want to parse. The file contains both male and female names.
Open Parser
This stage defines whether to use a culture-specific domain grammar created in the Domain Editor or to define a domain-independent grammar. A culture-specific parsing grammar that you create in the Domain Editor is a validated parsing grammar that is associated with a culture and a domain. A domain-independent parsing grammar that you create in Open Parser is a validated parsing grammar that is not associated with a culture and domain.
In this template, the parsing grammar is defined as a domain-independent grammar.
The Open Parser stage contains a parsing grammar that defines the following commands and expressions:
%Tokenizeis set to None. WhenTokenizeis set toNone, the parsing grammar rule must include any spaces or other token separators within its rule definition.%InputFieldis set to parse input data from the Name field.%OutputFieldsis set to copy parsed data into two fields: LastName and FirstName.
The <root> expression defines the pattern for Chinese names:
- One occurrence of LastName
- One to three occurrences of FirstName
The rule variables that define the domain must use the same names as the output fields defined in the required OutputFields command.
The CJKCharacter rule variable defines the character pattern for Chinese/ Japanese/Korean (CJK). The character pattern is defined so as to only use characters that are letters.The rule is:
<CJKCharacter> = @RegEx("([\p{InCJKUnifiedIdeographs}&&\p{L}])"); - The regular expression
\p{InX}is used to indicate a Unicode block for a certain culture, in whichXis the culture. In this instance the culture is CJKUnifiedIdeographs. - In regular expressions, a character class is a set of characters that you want to match. For example, [aeiou] is the character class containing only vowels. Character classes may appear within other character classes, and may be composed by the union operator (implicit) and the intersection operator (&&). The union operator denotes a class that contains every character that is in at least one of its operand classes. The intersection operator denotes a class that contains every character that overlaps the intersected Unicode blocks.
- The regular expression
\p{L}is used to indicate the Unicode block that includes only letters.
To test the parsing grammar, click the Preview tab. Type the names shown below in the Name field and then click Preview.
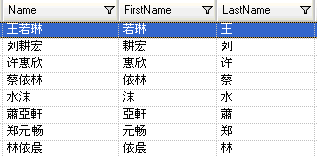
You can also type other valid and invalid names to see how the input data is parsed.
You can use the Trace feature to see a graphical representation of either the final parsing results or to step through the parsing events. Click the link in the Trace column to see the Trace Details for the data row.
Write to File
The template contains one Write to File stage. In addition to the input field, the output file contains the LastName, and FirstName fields. Select a match results in the Match Results List and then click Remove.